文章地址:https://ieeexplore.ieee.org/document/7929954
标题:Distance-Aware Encoding of Numerical Values for Privacy-Preserving Record Linkage
作者:Dimitrios Karapiperis; Aris Gkoulalas-Divanis; Vassilios S. Verykios
发表会议:33rd IEEE International Conference on Data Engineering, ICDE 2017
目前被引用次数:4(2019.01.08)
本文是ICDE上面的一篇短文,讲了一种数据编码方案,可以用在PPRL(Privacy-Preserving Record Linkage) 中。简单来说就是可以在匿名空间大致求出两个数据的差。直观感知上来看有点像密码学中的在密文中计算。
下面是本文的笔记,序号和论文中的序号一样,有些地方我觉得对这篇文章的理解不重要,我跳过了,建议先看一下原文再来看我的笔记。
- 1 Introduction
- 2 Embedding Numerical Values into the Binary Hamming Space
- 2.1 Specifying the Optimal Size of Bit Vectors
- 2.2 Specifying the Distance Threshold
- 3 Experimental Evaluation
1 Introduction
在接触本文之前首先应该对 Record Linkage 概念有一个基本的理解。我们看一下Wiki中的定义:
Record Linkage (RL) is the task of finding records in a data set that refer to the same entity across different data sources (e.g., data files, books, websites, and databases).
简单地来说就是在不同的数据库中,如何识别两个记录项是描述的同一个实体?最简单的方法自然是看每个字段是否一样了。比如:
| Data set | Name | Date of birth | City |
|---|---|---|---|
| Data set 1 | William J. Smith | 1/2/73 | Berkeley |
| Data set 2 | William J. Smith | 1/2/73 | Berkeley |
那么很显然我们就知道数据集1中的 William J.Smith 和数据集2中的 William J.Smith 是描述的同一个人了,或者说非要找茬的话,我们会认为这两个 William 很可能是同一个人。
当然,现实的问题肯定是会慢慢出现的,比如,由于数据收集者的习惯不同,在数据集2中的数据可能是这样的:
| Data set | Name | Date of birth | City |
|---|---|---|---|
| Data set 1 | William J. Smith | 1/2/73 | Berkeley |
| Data set 2 | William J. Smith | 1973.01.02 | Berkeley |
所以一般来说在进行数据比较之前,需要进行一个数据预处理的过程 (Data Pre-processing),把数据变成统一的格式,如日期,姓名顺序以及城市名称等。
并不是数据经过预处理就可以进行精确匹配了,因为现实生活中收集到的数据通常是含有噪声的,或者通常是不太精确的。比如数据集1中的William和数据集2中的Wiliam可能是同一个人,因为数据收集的时候少看了一个字母。所以我们一般来说不进行精确匹配,而是看两个记录项的相似度。比如对于字符串,比较相似度可以采用 Edit Distance 的方法。
应用的需求总是越来越高,在之前的假定中,假如数据集A中有m条记录,数据集B中有n条记录,那么他们比较的时候需要比较mn次,对于庞大的数据集来说,这个复杂度是比较高的。所以为了加速,有了很多索引技术(Indexing),用了索引之后,可能就不需要比较那么多次了。索引技术我们这里暂不涉及。
在这个流程下,经过 “Pre-processing, Indexing, Comparison” 之后,Record Linkage 基本上就解决了。大致思路就是把数据处理好,然后放到一起来比较。
仔细思考之后,其实还存在一个潜在的问题:数据放到一起,意味着有人要交出自己的数据,而数据又是和个人隐私息息相关的,所以人们就想,能不能在不泄露数据的情况下完成这么个任务呢?所以就有了我们的 Privacy-preserving record linkage 这个大框架了。
PPRL中的过程和RL其实是一模一样的,大致上分为预处理,索引,比较三个过程,不过所有的操作过程都要是满足privacy-preserving的。
一想到privacy-preserving,一个很自然的想法就是我们把字符串加密,然后在密文上面进行相似度比较不就好了嘛。这个愿景看上去是很好的,可是操作起来好像没有这么容易。
在当前的研究中,对于字符串的PPRL方案,一个很经典的方案就是采用布隆过滤器 (bloom filter)。这个方法由于大多数论文都会引用,所以我在下一篇文章中也会讲一下。
当前已经很多文献提出了PPRL的一些方法,但是很多方法在处理的过程中都是将数字类型的数据当成是字符串来求解,这无疑会带来很多误差,比如数字199和99,如果认为是字符串的话,他们只相差一个字符,因而会被认为是很相近的,但是实际上199和99相差很多。另一个例子是99和100,如果认为是字符串,99和100相差很多,如果认为是数字则99和100是很接近的。本篇论文结局的实际上就是在PPRL中如何处理数字。
2 Embedding Numerical Values into the Binary Hamming Space
本文中提到的 BV 方案是将原始数据编码到一个匿名空间,然后再匿名空间中求得两个数据的相似性。在编码之前,我们首先需要知道以下一些信息:
- $s$ 个分布在 $[b1, b2]$ 的随机数,其中 $[b1,b2]$ 是原始数据分布范围,并且 $u=b2-b1$ 表示原始数据分布区间长度。
- 数据区间参数 $t$,待会会说明这个参数的作用
2.1 Specifying the Optimal Size of Bit Vectors
假如我们要编码的数据是 $x$,给定随机数$r_i$, 首先我们定义一个哈希方程:
这个哈希方程的意思是,根据随机数 $r_i$ 产生一个随机区间,然后如果 $x$ 在这个区间中,则编码结果是1,如果不在这个区间中,编码结果是0。为了更加形象地说明这个编码过程,论文里面给了一个编码的案例:
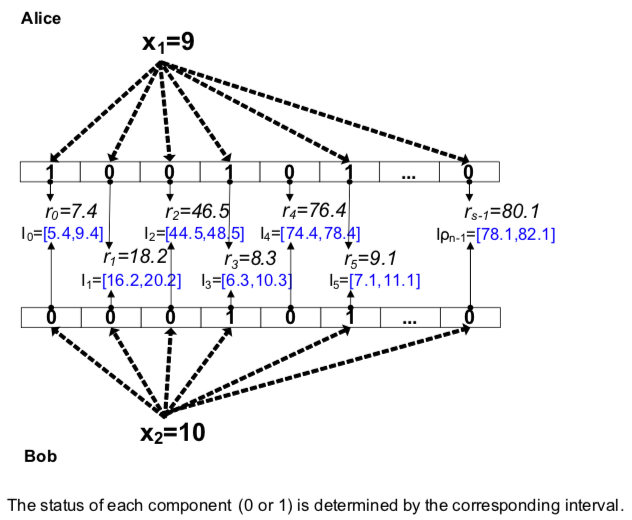
假如 $t=2$,需要编码的数据分别是9和10,然后给定地随机数是 $\{7.4, 18.2, 46.5, 8.3, 76.4, 9.1, …, 80.1\}$,那么经过BV方案编码的结果分别如上面所示。
根据这个方案,我们可以发现,如果两个数据很接近,那么他们就很可能同样的位置都是0或者都是1。那么如何去看这之间的 “相近” 关联呢?接下来作者提了几个定理 (引理):
Lemma 1 The expected number $w$ of the components which are set in each bit vector is:
这个引理其实就是说一个数据编码的结果中有多少个1,这个引理很简单也很重要,根据这个引理,我们可以发现,在匿名空间中,每个数对应的1的个数都差不多,所以对于拿到匿名数据的人来说,他很难获得关于原始数据的信息。
Lemma 2 The expected number $v$ of common components that are set in a pair of bit vectors, which correspond to numerical values with $d_E < 2t$, is:
这个引理是说两个数据 $x,y$ 编码的结果中有多少位都是1。自己思考一下也可以得到结论,因为我也不给出具体证明过程了。
2.2 Specifying the Distance Threshold
接下来就给出铭文空间中对应的数值差和匿名空间中对应的汉明距离之间的关系了。
Theorem 1 The expected Hamming distance $E[d_H]$ between a pair of bit vectors which correspond to numerical values with $d_E < 2t$ is:
通过这个定理我们可以发现明文中的差值 $d_E$ 和匿名空间中的汉明距离$d_H$是有一定的对应关系的,所以可以用来做相似度比较。
3 Experimental Evaluation
由于是短文,本文没有涉及很多的实验,并且这个方法已经有了理论支持,也不那么受实验影响,本文中的实验还是比较少的。由于目前没有很多的对数字进行PPRL的成果,所以对比对象仅仅有NBF着一个方法,这个方法可以参考论文“Privacy-preserving matching of similar patients”。
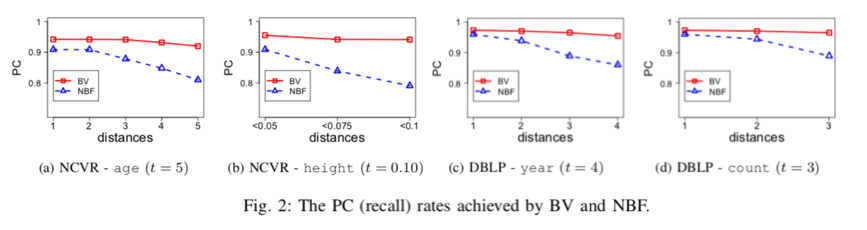
这里的PC指的是recall,我们可以看出,和NBF相比较,BV机制还是好一些的。由于没有给出其他实验,这个方法暂且来说还是很不错的。
当然,在本文中作者还分析了一些误差计算和参数的选取,本文目前只介绍了这篇文章的大致方法,对于论文中公式不了解的地方可以和我单独讨论。
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


