数据结构
Pandas是基于Numpy的库,其拥有两种数据结构:Series 和 DataFrame。

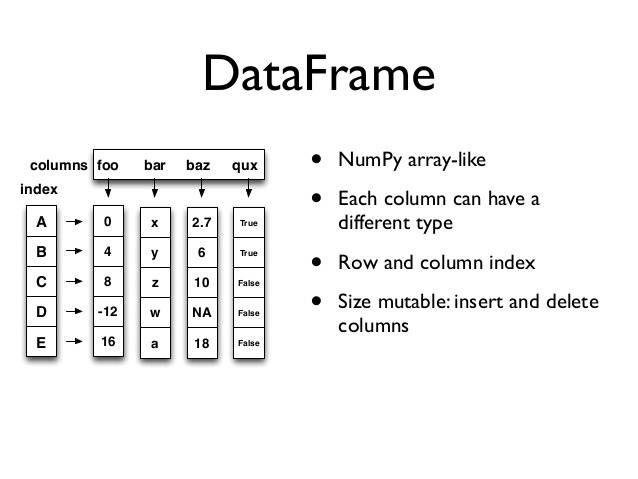
案例
创建空DataFrame并一行一行写入数据
1 | import pandas as pd |
运行结果:
1 | x y z |
写文件:
1 | df.to_csv('output.csv', index=None) |
过滤:取某些行
取行
1 | mult_row = df.loc[1:4] |
结果 ,注意这里的行是包括第四行的。
1 | x y z |
根据条件过过滤
错误用法
1 | # wrong example |
正确的过滤用法
1 | # right example |
上面两个的输出都是,注意索引:
1 | x y z |
过滤:取某些列
取列
1 | # 取单个列 |
取列并转换为列表
1 | x_list = df['x'].tolist() |
取某个值
1 | print(df.loc[2][2]) |

