本视频来源于Shusen Wang讲解的《分布式机器学习》,总共有三讲,内容和连接如下:
上节课讲了并行计算的基础知识,讲了如何利用 MapReduce 做梯度下降,还分析了通信和同步造成的代价。这节课讲解不同于 MapReduce 的两种编程模型,Parameter Server(参数服务器)和 Decentralized Network(去中心化网络),以及如何用这两种架构实现梯度下降。主要有以下几点:
- Parameter Server(参数服务器),以及用Parameter Server实现异步梯度下降。
- Decentralized Network(去中心化网络), 以及用Decentralized Network实现梯度下降。
- Parallel Computing(并行计算)和 Distributed Computing(分布式计算)的异同。
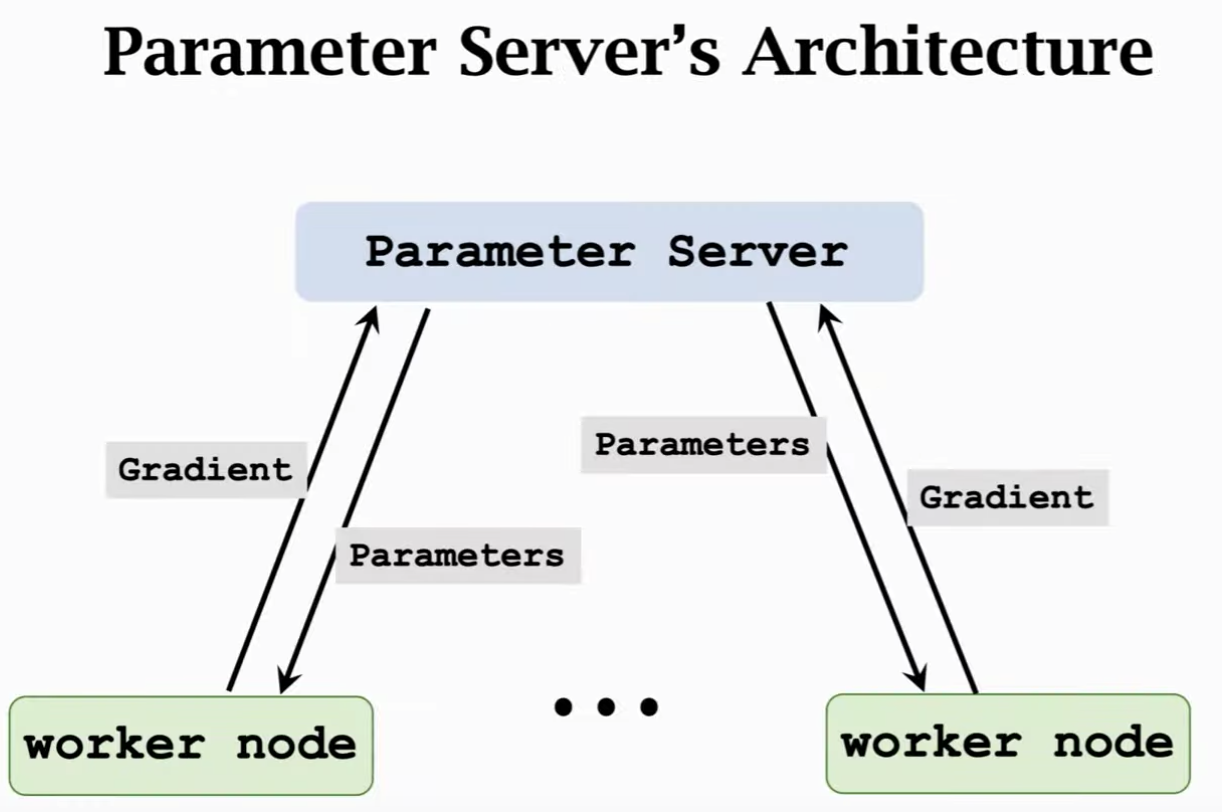
由上图可知,parameter server其实是一种client-server架构,有多个节点,一个或几个节点作为server,其他节点作为worker。worker来算梯度,server来更新模型参数。其和MapReduce看起来还是很像的。和MapReduce不同的地方在于 Parameter server是异步的,MapReduce只有等map都完成了才能做reduce操作。如果想用parameter做实际项目,建议用ray这个开源项目。

我们先来看一下什么是同步算法,同步算法中,每一轮需要等待所有的worker完成任务才能往下进行。如左图所示。异步算法中,不需要进行同步的操作,右图所示。由于没有同步,worker就不用等其他worker了。因此运行效率很高,因为worker一直在做计算。那么是怎么做的呢:

在执行的过程中,worker不用等其他节点,就重复计算。这个过程已经被证明是收敛的了。从实现上看,异步算法比同步算法收敛要快。理论上,异步算法有着更低的收敛率。但是异步算法也容易受异常节点影响:

上图其实很容易理解,别人都做了好几轮了,慢的节点才做了一轮,那么它的梯度实际上是有害的。接下来我们将Decentralized Network。
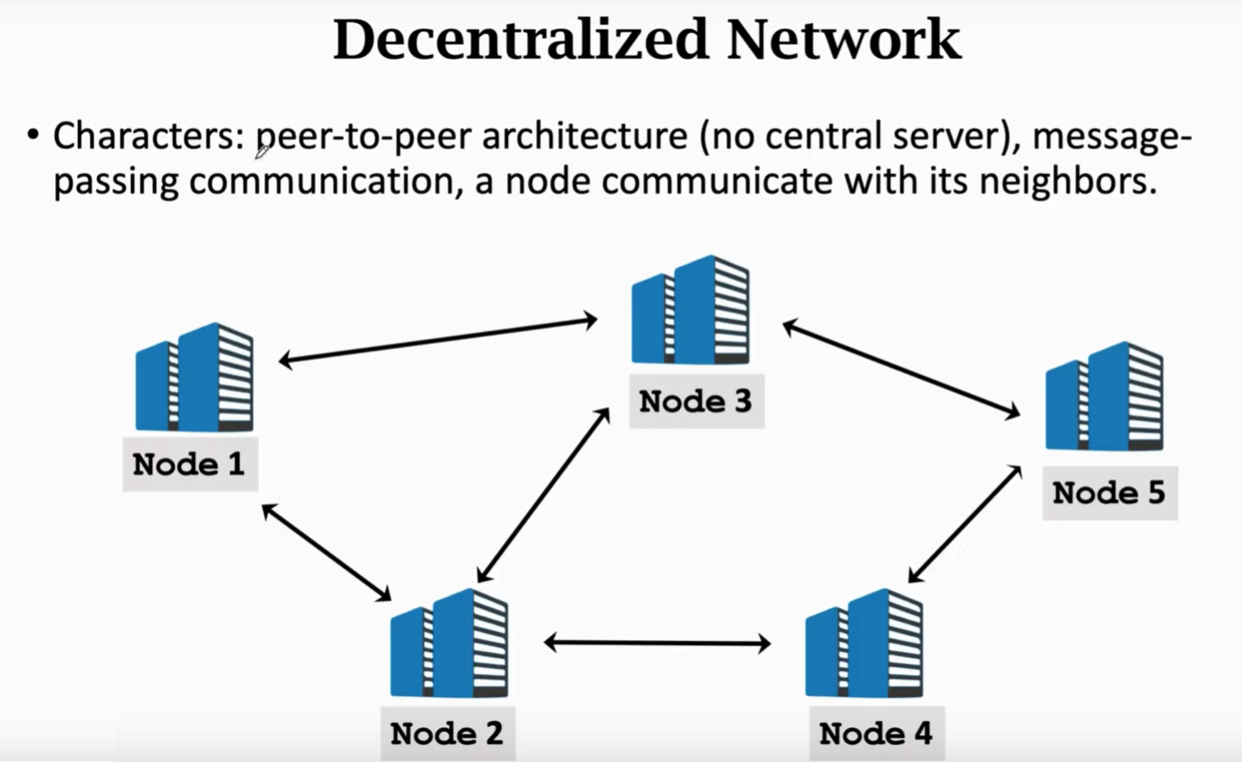
去中心化网络没有一个中心节点,采用message passing进行通信。梯度下降的过程原理如下:
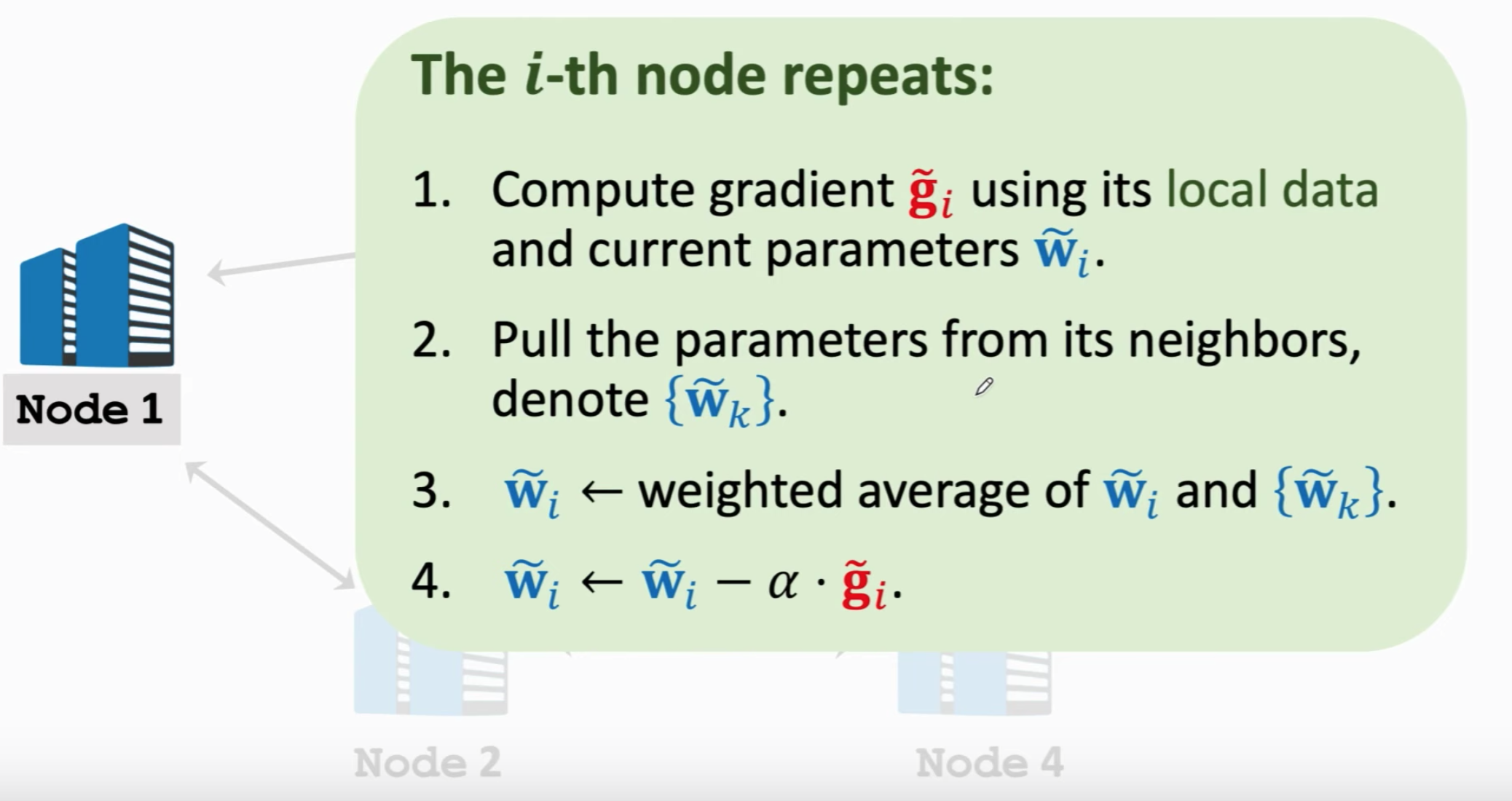
其有着这么一些性质:
- Decentralized GD 和 SGD 都被证明了是收敛的
- Decentralized GD的收敛率和图有关:
- 如果节点构成完全图,那么收敛很快
- 如果图不是全连通的,那么不收敛
课程的后面是总结,还讲了并行计算和分布式计算的一些区别(实际上没有明显的区别),在此就不一一展开了。
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


