本视频来源于Shusen Wang讲解的《分布式机器学习》,总共有三讲,内容和连接如下:
这节课的内容是联邦学习。联邦学习是一种特殊的分布式机器学习,是最近两年机器学习领域的一个大热门。联邦学习和传统分布式学习有什么区别呢?什么是Federated Averaging算法?联邦学习有哪些研究方向呢?我将从技术的角度进行解答。 这节课的主要内容:
- 分布式机器学习
- 联邦学习和传统分布式学习的区别
- 联邦学习中的通信问题
- Federated Averaging算法
- 联邦学习中的隐私泄露和隐私保护
- 联邦学习中的安全问题(拜占庭错误、data poisoning、model poisoning)
- 总结
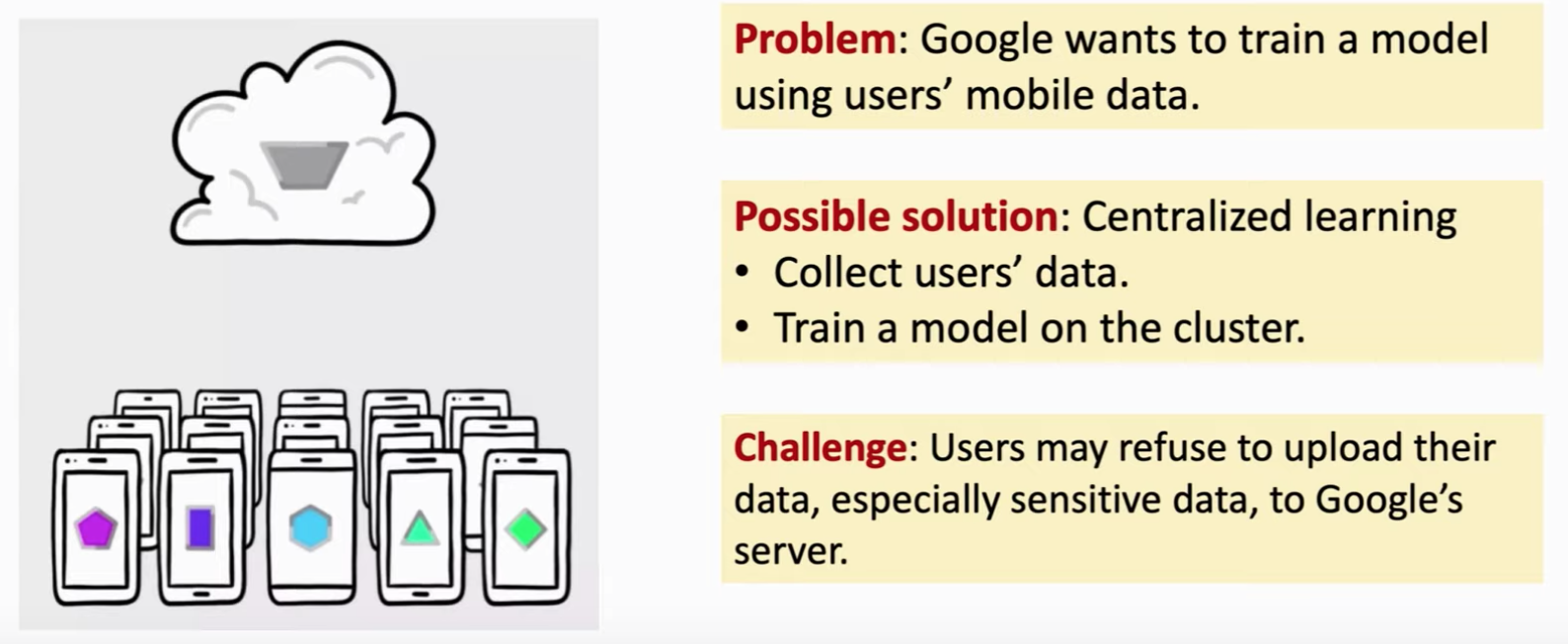
联邦学习有很实际的应用,如移动端会产生数据,但是server,比如谷歌想要从用户那里的数据进行学习。那么一种显然的解决方法就是把数据收集起来,然后学习。但是,现实生活中有着一定的限制,可能处于法律要求或者用户拒绝上传属于,没有一个中心节点可以得到所有的数据,呢么我们该如何去学习模型呢?这个就叫联邦学习。

联邦学习和传统的分布式学习有什么区别呢,主要有以下四点:
- 用户对于自己的设备和有着控制权。
- Worker节点是不稳定的,比如手机可能突然就没电了,或者进入了电梯突然没信号了。
- 通信代价往往比计算代价要高。
- 分布在Worker节点上的数据并不是独立同分布的(not IID)。因此很多已有的减少通信次数的算法就不适用了。
- 节点负载不平衡,有的设备数据多有的设备数据少。比如有的用户几天拍一张照片有的用户一天拍好多照片,这给建模带来了困难。如果给图片的权重一样,那么模型可能往往取决于拍图片多的用户,拍照少的用户就被忽略了。如果用户的权重相同,这样学出来的模型对拍照多的用户又不太好了。负载不平衡也给计算带来了挑战,数据少的用户可能一下子算了很多epoc了,数据多的用户还早着。这一点上,联邦学习不像传统的分布式学习可以做负载均衡,即将一个节点的数据转移到另一个节点。
对于联邦学习,当下有这么几个研究热点:
Research Direction 1: Communication Efficiency
我们回顾一下并行梯度下降中(parallel gradient descent),第 $i$ 个worker执行了哪些任务
- 从server接收模型参数 $w$
- 根据 $w$ 和本地数据计算梯度 $g_i$
- 将 $g_i$ 发送给server
然后server接收了所有用户的 $g_i$ 之后,这么做:
- 接收 $g_1, g_2, …, g_m$
- 计算:$g = g_1 + g_2 + … + g_m$
- 做一次梯度下降,更新模型参数:$w = w - \alpha \cdot g$
- 然后将新的参数发送给用户,等待用户数据重复执行下一轮迭代
那么我们看一下 federated averaging algorithm,其可以用更少的通信次数达到收敛。
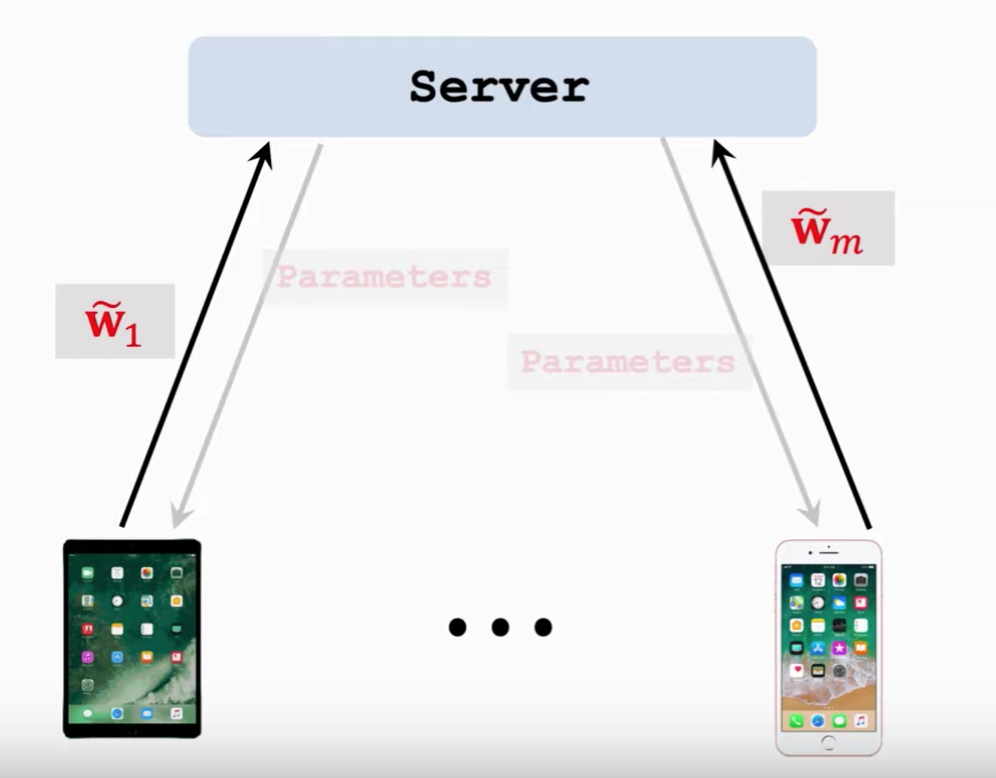
一开始还是sever把参数 $w$ 发送给worker节点,但是worker和之前就不一样了:
- 接收参数 $w$
- 迭代以下过程:
- 利用 $w$ 和本地数据计算梯度 $g$
- 本地化更新:$w = w - \alpha\cdot g$
- 将 $\widetilde{w}_{i}=w$ 发送给server
然后server接收了全部的 $\widetilde{w}_i$ 之后,这么更新
- 从用户那里接收 $\widetilde{w}_i$
- 用以下方程更新 $w \leftarrow \frac{1}{m}\left(\widetilde{w}_{1}+\cdots+\widetilde{w}_{m}\right)$,这个新的模型就叫 $w$,下一轮迭代的时候再把这个新的 $w$ 发送给所有节点。

我们把Federated Averaging和梯度下降对比一下,如果以communication为横轴,那么有上图,可见用相同次数的通信,Federated Averaging收敛的更快。两次通信之间Federated Averaging让worker节点做大量计算,以牺牲计算量为代价换取更小的通信次数。如果横轴以epochs为横轴,有以下结果:

我们可以看到相同次数的epochs,梯度下降的收敛更快。

Federated Averaging算法首次由[1]提出,但是没有理论证明,论文[2]证明了Federated Averaging算法对于对同分布数据是收敛的,论文[3]首次证明了Federated Averaging算法对非独立同分布的数据也是收敛的,论文[4]和[3]得到了类似的结论,但是结果晚一点出来。

减少通信次数是个大问题,减少通信次数并不是Federated Averagin这篇文章首次提出的,这里就列了一些文章,但是这些文章大都要求数据独立同分布,这就难以用到联邦学习中。[4]不要求数据独立同分布,但是不适用于深度学习,神经网络很难求对偶问题。
Research Direction 2: Privacy

联邦学习中,用户的数据是始终没有离开用户的,那么数据是否安全呢?我们注意到算梯度的过程中实际上就是对数据进行一个变化,将数据映射到梯度。

虽然数据没有发出去,但是梯度是几乎包含数据所有信息的,所以一定程度上,可以通过梯度反推出数据的。

论文[1]说如果一个学习的模型是有用的,那么其肯定泄露了训练数据的信息,当然这点事很显然的。[2]提出额Model Inversion方法可以根据模型反推出数据,但是攻击效果不太好,因为Model Inversion只能看到最后的参数,联邦学习中,我们可以看到每一轮的梯度都是知道的,那么可以反推出更多的信息。[1]和[3]就做了这样的事情,虽然不能完全反推出原始数据,但是可以推出很多的特征,比如用户是男是女。

文章[1]的大致思路如上,将梯度作为输入特征,然后学习一个分类器。其根本原理就是梯度带有用户信息。那么有没有办法抵御这种攻击呢,当前的主流做法就是加噪声,比如 DP。

通常是往梯度里面加噪声,但是实验效果并不理想,噪声大了的话,收敛速度就很慢,甚至学习过程进行不下去,因为目标函数不下降了。噪声小了的话隐私保护效果就不好,还是可以反推出用户数据。加噪声会导致测试准确率下降几个百分点,这在工业界是很难接受的,往往下降一个百分点会带来几十万的损失。
Research Direction 3: Adversarial Robustness
第三个研究热点让联邦学习可以抵御拜占庭错误和恶意攻击。简单说就是worker中出了叛徒,如何学到更好地模型。

[1] 提出了数据poisoning attack,[2]提出了模型poisoning 攻击。有了攻击自然有防御措施,这里就列了三种防御措施。很多方法都假设数据是独立同分布的,但这点现实生活并不满足。总而言之,攻击比较容易,防御比较困难,还没有真正有效的防御。

总结一下,联邦学习是一种比较特殊的分布式学习,目标是让多个用户不共享数据前提下共同训练一个模型,联邦学习有着其特有的挑战,首先数据不是独立同分布,另一个是数据通信代价高。然后还讲了几个研究挑战点。
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


