本章节讲解神经网络,组织结构如下:
- Advice for Applying Machine Learning
- Deciding What to Try Next
- Evaluating a Hypothesis
- Model Selection and Train Validation_Test Sets
- Diagnosing Bias vs. Variance
- Regularization and Bias_Variance
- Learning Curves
Deciding What to Try Next
到目前为止,已经介绍了不同的算法了,已经可以算是一个了解许多机器学习算法的小专家了。

对于懂机器学习算法的人,不同人之间的差距依然很大。我们仍然以房价预测为例,假设我们的最小化目标为:
我们在学习到了一个模型之后,发现对于新的数据拟合的效果不是很好,这时候我们下一步可以做些什么呢?
- 获得更多的训练样本:这通常是有效的,但是代价一般也比较大。
- 尝试减少特征的数量
- 尝试增加特征的数量
- 尝试增加多项式特征
- 尝试减少正则化程度 $\lambda$
- 尝试增加正则化程度 $\lambda$
我们不应该随机选择上面的某种方法来改进我们的算法,而是运用一些机器学习诊断法来帮助我们知道上面哪些方法对我们的算法是有效的。
在接下来的两段视频中,我首先介绍怎样评估机器学习算法的性能,然后在之后的几段视频中,我将开始讨论这些方法,它们也被称为”机器学习诊断法”。“诊断法”的意思是:这是一种测试法,你通过执行这种测试,能够深入了解某种算法到底是否有用。这通常也能够告诉你,要想改进一种算法的效果,什么样的尝试,才是有意义的。在这一系列的视频中我们将介绍具体的诊断法,但我要提前说明一点的是,这些诊断法的执行和实现,是需要花些时间的,有时候确实需要花很多时间来理解和实现,但这样做的确是把时间用在了刀刃上,因为这些方法让你在开发学习算法时,节省了几个月的时间,因此,在接下来几节课中,我将先来介绍如何评价你的学习算法。在此之后,我将介绍一些诊断法,希望能让你更清楚。在接下来的尝试中,如何选择更有意义的方法。
Evaluating a Hypothesis
本节介绍如何用学过的算法来评估假设函数,以后再以此为基础讨论如何避免过拟合和欠拟合的问题。
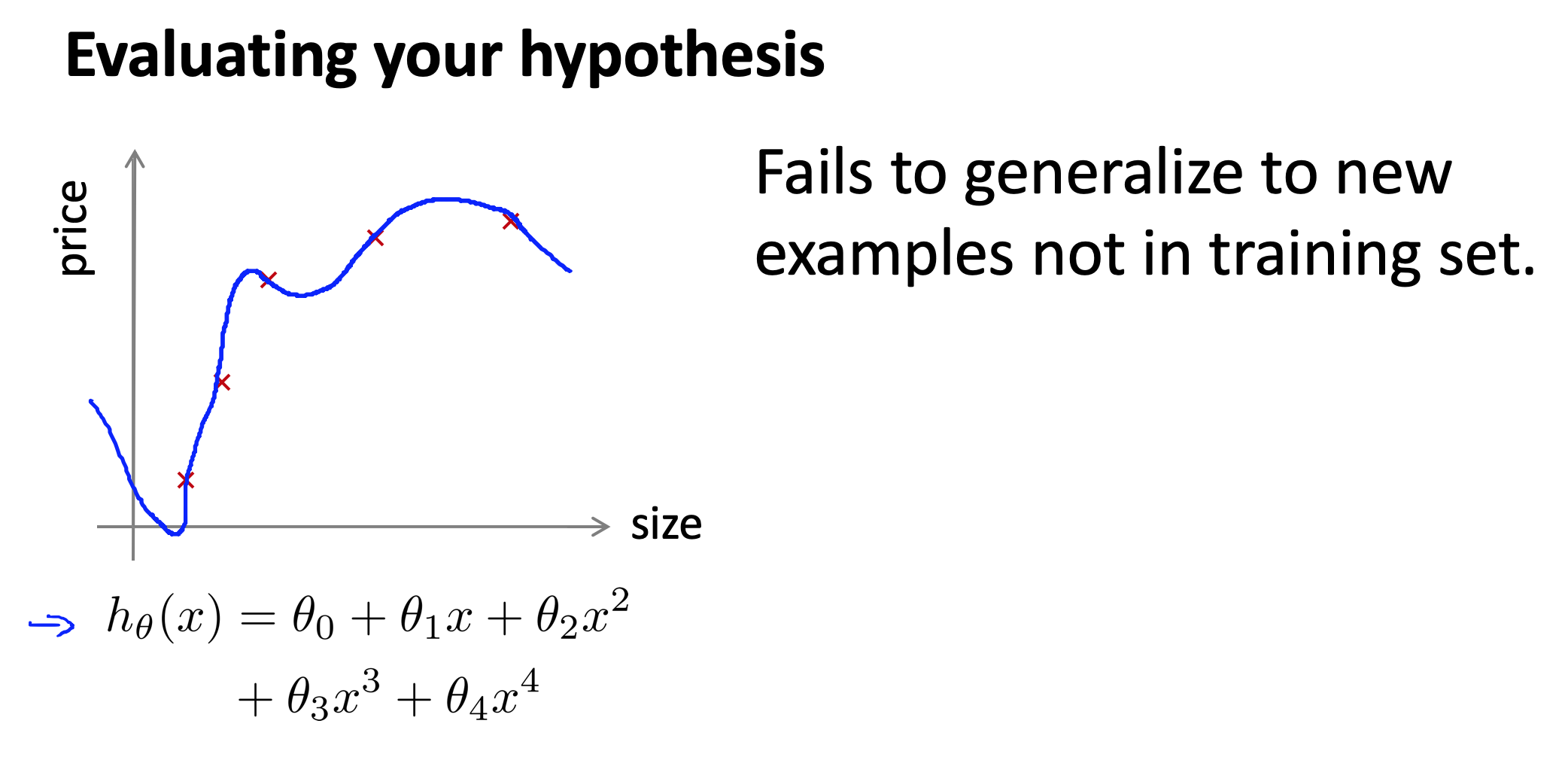
我们在优化的过程中,考虑的是选择 $\theta$ 使得训练误差最小化。那么训练误差最小是不是就一定好呢,当然不是的,比如上图的例子就是过拟合的。
那么我们如何判断一个假设函数是过拟合的呢?为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”,然后再分成训练集和测试集。

那么我们有以下几种方法去计算代价函数:
- 对于线性回归模型,利用测试数据代入代价函数
- 对于逻辑回归模型:
- 用测试数据代入代价函数
- 可以计算误分类的比例,即对于每个输入,先对其进行分类,再看分类准确率。
Model Selection and Train Validation_Test Sets
依然是房价预测,加入我们要在以下是个二次项模型中进行选择,应该选择哪一个 $d$ 呢?
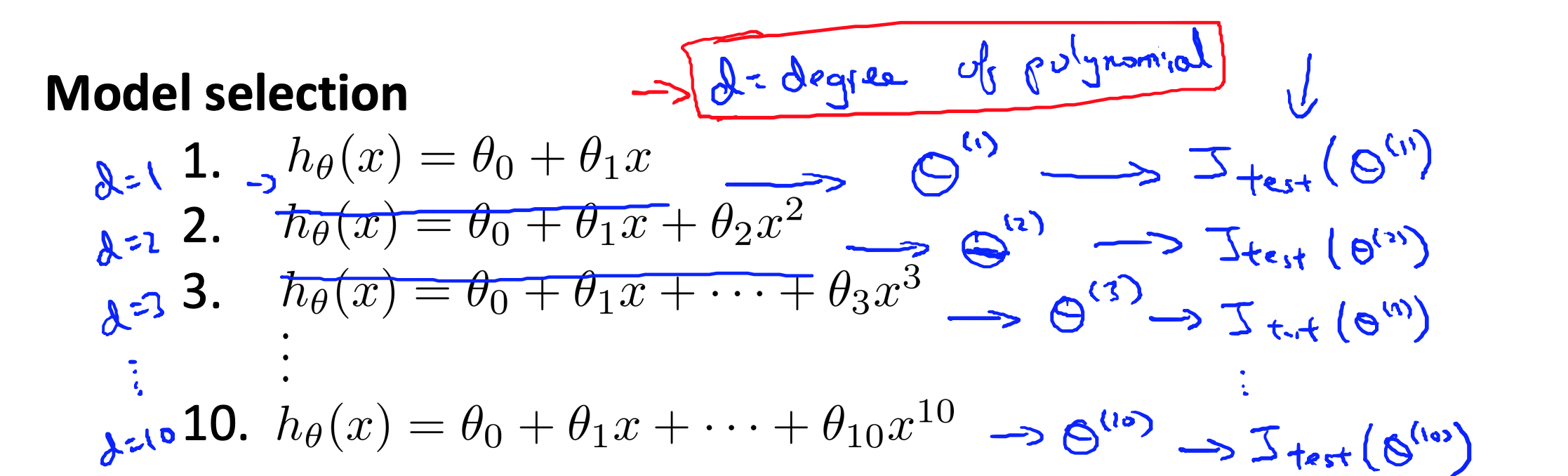
我们知道,越高次越能拟合训练集,但是可能对于测试集并不一定有好,那么能不能这么做:
- 把数据分为70%训练接和30%测试集。
- 用训练集训练10个模型,对于这是个模型,用测试集计算误差,对应 $J_{test}(\Theta^{(1)})… J_{test}(\Theta^{(10)})$
- 根据测试集上误差小的选择 $d$。
以上步骤是有问题的,因为选出来的 $d$ 就是在测试集上选的,所以不能说选出来的 $d$ 就是最好的。就像训练集上训练的模型需要用测试数据去算误差。
所以我们需要使用交叉验证集来帮助选择模型。即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集。

所以现在的模型选择方法为:
使用训练集训练出10个模型
用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
选取代价函数值最小的模型
用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
误差的定义如下:
Diagnosing Bias vs. Variance
当我们巡行一个算法的时候,如果结果不好,一般是来那个种情况:要么是偏差(Bias)较大,一种是方差(Variance)较大。换句话说,要么是欠拟合,要么是过拟合。

我们通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析:

一般来说有以下两种情况:
- 对于训练集,当 $d$ 较小时,模型拟合程度更低,误差较大;随着 $d$ 的增长,拟合程度提高,误差减小。
- 对于交叉验证集,当 $d$ 较小时,模型拟合程度低,误差较大;但是随着 $d$ 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
那么如果我们的交叉验证集误差较大,我们如何判断是方差还是偏差呢?根据上面的图表,我们知道:

即:
- 训练集误差和交叉验证集误差近似时:偏差/欠拟合
- 交叉验证集误差远大于训练集误差时:方差/过拟合
Regularization and Bias_Variance
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能会正则化的程度太高或太小了,即我们在选择λ的值时也需要思考与刚才选择多项式模型次数类似的问题。
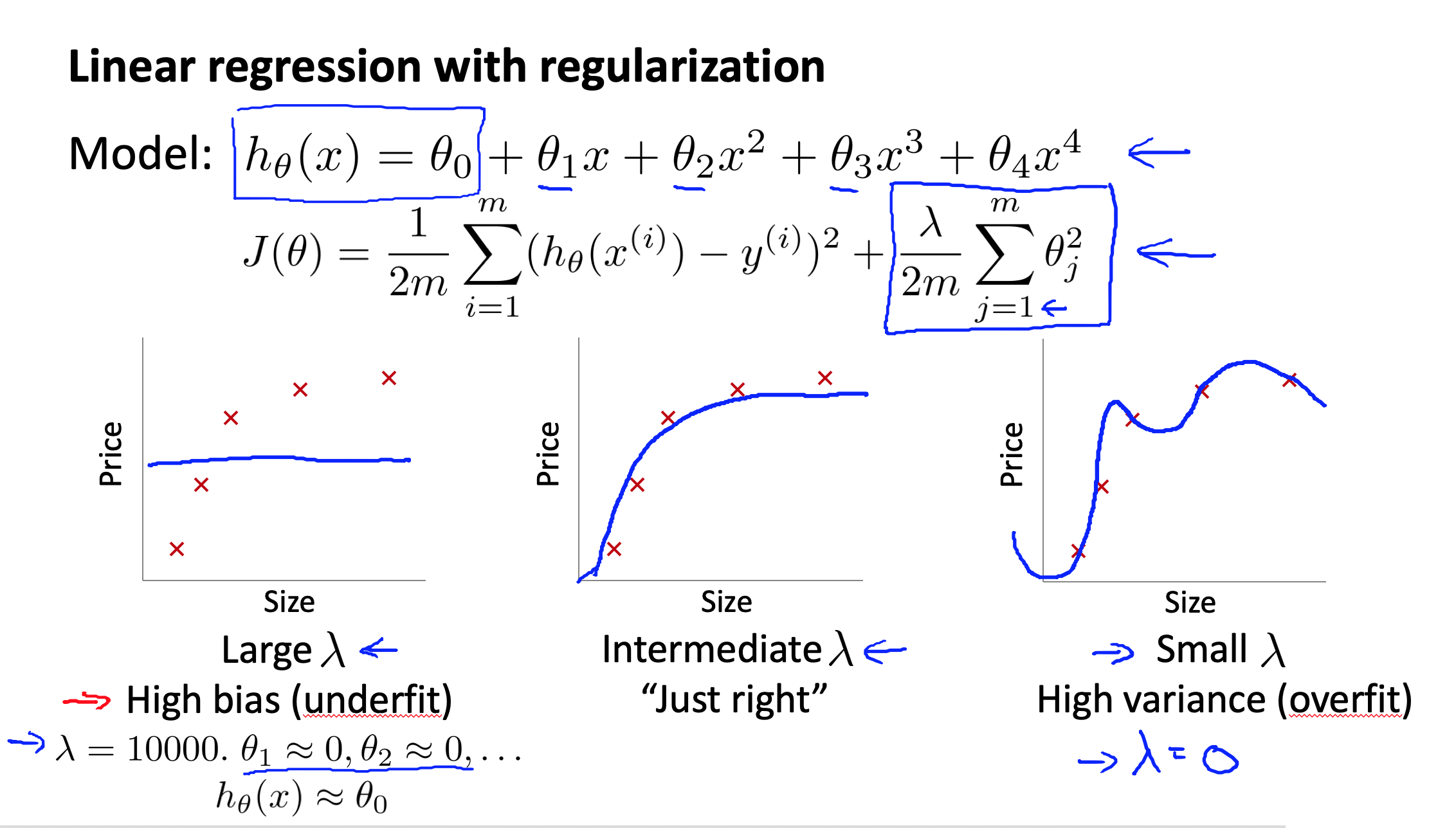
我们可以选择一系列的想要测试的 $\lambda$ 值,通常是 0-10之间的呈现2倍关系的值(如:$0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10$共12个)。 我们同样把数据分为训练集、交叉验证集和测试集。

选择$\lambda$的方法为:
- 使用训练集训练出12个不同程度正则化的模型
- 用12个模型分别对交叉验证集计算的出交叉验证误差
- 选择得出交叉验证误差最小的模型
- 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:

- 当 $\lambda$ 较小时,训练集误差较小(过拟合)而交叉验证集误差较大
- 随着 $\lambda$ 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
这样不停地尝试过程中,我们就可以得到更好的参数了。
Learning Curves
学习曲线可以用来判断某一个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量($m$)的函数绘制的图表。

考虑模型 $h_\theta(x)=\theta_0 + \theta_1 x = \theta_2 x^2$,我们可以画出随着训练数据集误差和交叉验证数据集误差随着训练样本数量 $m$ 的变化。当训练样本为1、2、3时,训练数据集的误差为0,即当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。

那么如何利用学习曲线识别高偏差/欠拟合呢:作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观。即:在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。
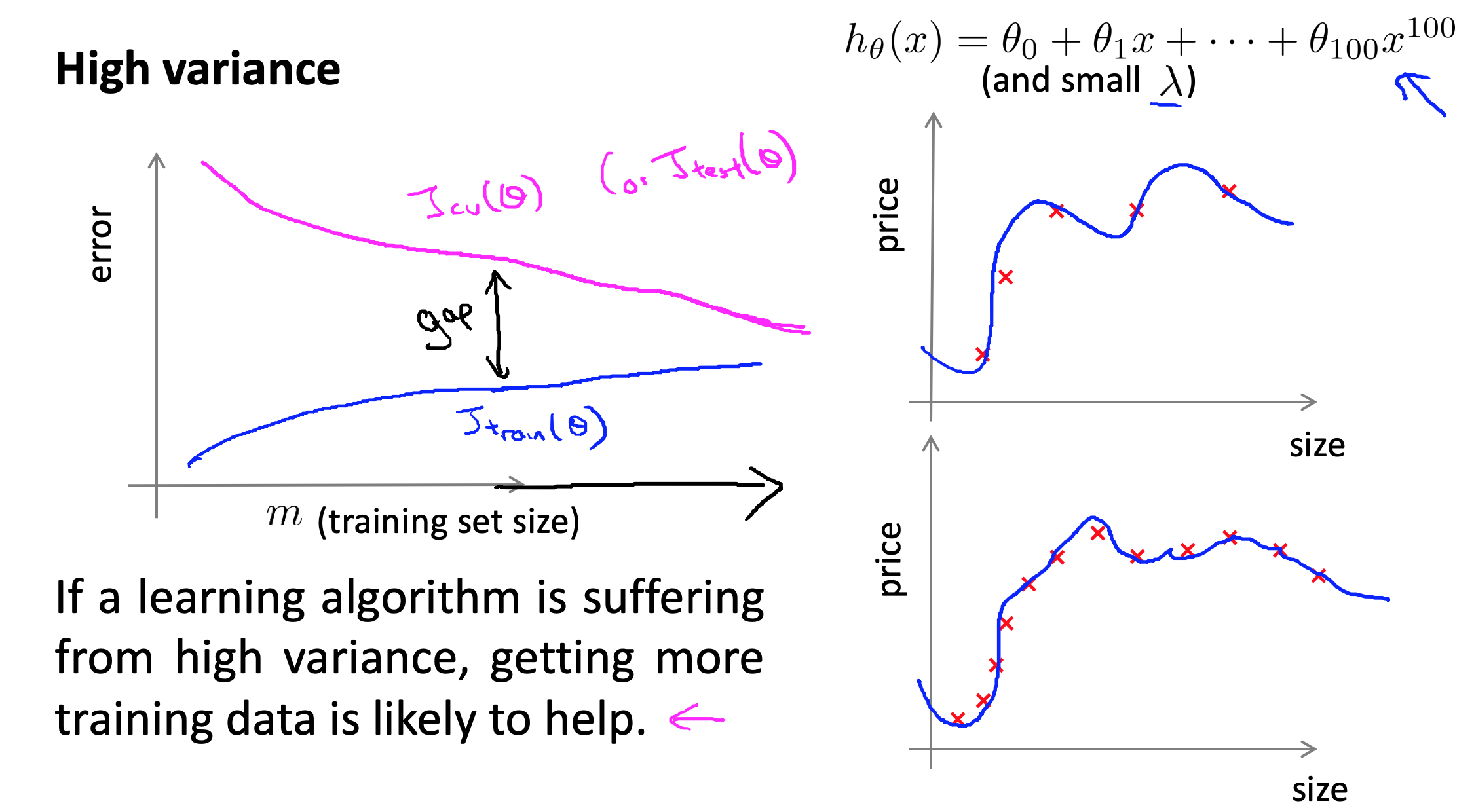
再看过拟合的情况:假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。即:在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。
Deciding What to Do Next (revisited)
我们已经介绍了怎样评价一个学习算法,我们讨论了模型选择问题,偏差和方差的问题。那么这些诊断法则怎样帮助我们判断,哪些方法可能有助于改进学习算法的效果,而哪些可能是徒劳的呢?

让我们再次回到最开始的例子,在那里寻找答案,这就是我们之前的例子。回顾 1.1 中提出的六种可选的下一步,让我们来看一看我们在什么情况下应该怎样选择:
获得更多的训练样本——解决高方差
尝试减少特征的数量——解决高方差
尝试获得更多的特征——解决高偏差
尝试增加多项式特征——解决高偏差
尝试减少正则化程度λ——解决高偏差
尝试增加正则化程度λ——解决高方差
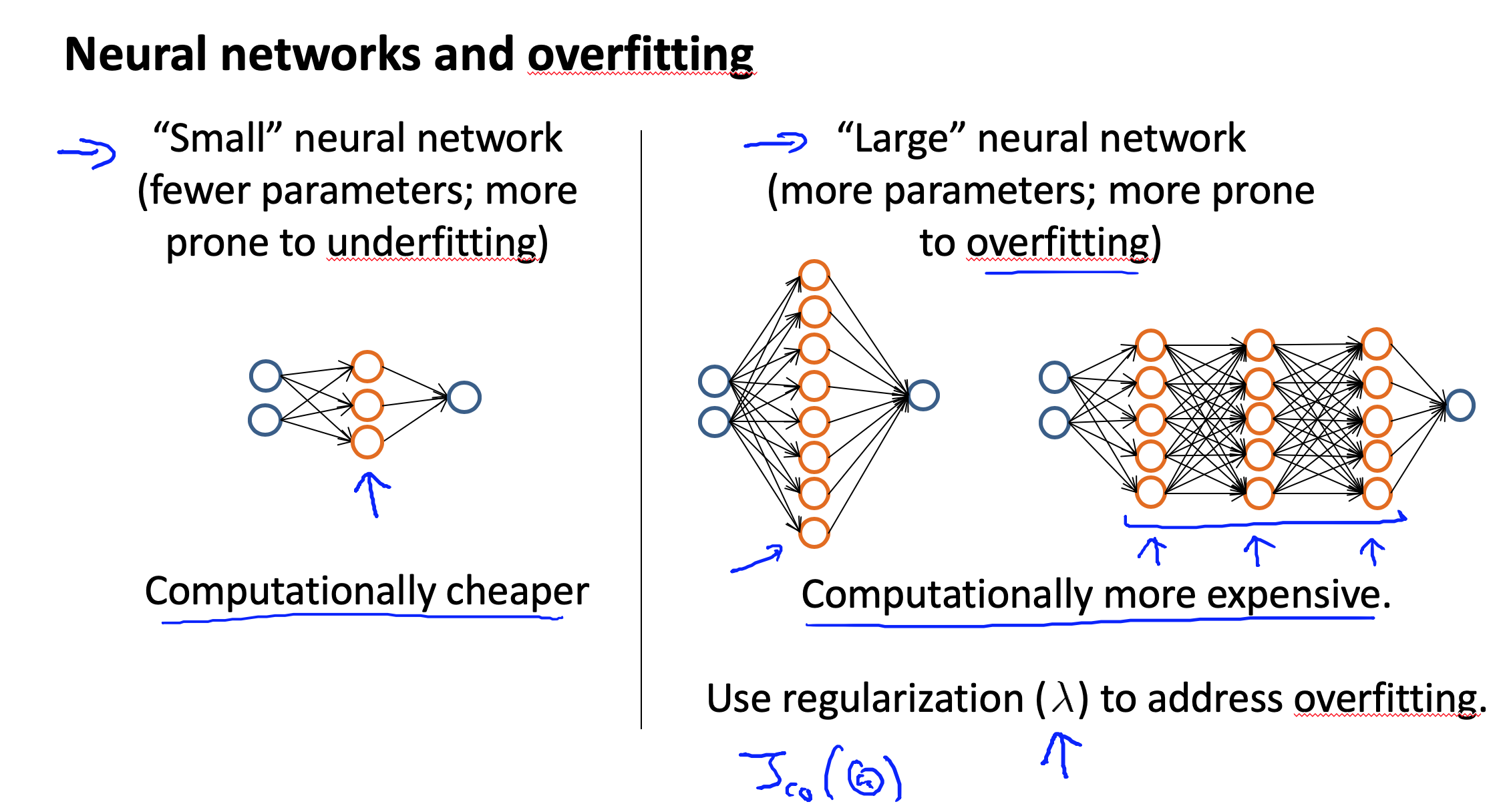
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,然后选择交叉验证集代价最小的神经网络。

