本篇内容讲一下论文《Federated Machine Learning: Concept and Applications》中的纵向联邦学习中的回归方法,因为在阅读论文的过程中,我觉得论文当中的写法比较confusing,所以重新梳理了一遍,争取公式的写法上不存在歧义。在阅读的过程中,主要有以下两个困惑的点:
- 公式7认为 $\left[!\left[L\right]!\right] = [![L_A]!] + [![L_B]!] + [![L_{AB}]!]$,理解上不存在为了,写成 $[![L]!] = [![L_A]!] \oplus [![L_B]!] \oplus [![L_{AB}]!]$ 更好;
- 公式8与公式9中 $[![d_i]!]x_i$ 和求和符号阅读起来比较困惑,一个密文和明文相乘是什么意思,密文求和是什么意思;
- 当然,细心的同学还会发现个小问题,就是 Loss 函数少了个 $\frac{1}{2}$,或者后面的偏导少了个2,好在不影响算法流程。
所以本篇博客重新梳理一下这个问题,首先对线性回归算法和同态加密进行一个简单的回顾,然后按照这篇论文中的思路对纵向联邦学习中的线性回归进行讲解。
上传后发现网页端加密的符号 $[[\cdot]]$ 被显示成了 $[![\cdot]!]$,读者自行体会一下。

背景知识
线性回归算法
线性回归的内容可以参考 吴恩达机器学习课程(4)-Linear Regression with Multiple Variables。为了方便描述,我们采用了论文《Federated Machine Learning: Concept and Applications》中的 loss 函数,当然我们默认这个文章中的 loss 中少写了一个 $\frac{1}{2}$ 的校正,下一节会提到。假如有 $m$ 条数据 $n$ 个特征, loss 函数为:
为了得到最优解,我们采用梯度下降方法,给定学习率 $\eta$,优化的过程为:
同态加密
更为主要的,Paillier 算法系统满足以下性质:
- 同态加法:$[![x+y]!] = [![x]!] \cdot [![y]!]$
- 同态乘法:$[![x\times y]!] = [![x]!] ^ y$
为了使得含义更明确,就这么记一下:$[![x+y]!] = [![x]!] \oplus [![y]!]$,以及 $[![x\times y]!] = [![x]!] \otimes y$,这样子根据就可以直接看出来密文上的操作是想做加法还是做乘法了。
关于 Paillier 算法系统是如何实现同态加法和同态乘法的,可以参考:密码学-公钥加密算法 Paillier。
联邦学习下线性回归算法
我们假设 A 端的数据为 $x_i^A$,B 端的数据为 $x_i^B, y_i$,那么线性回归对应的参数就是 $\Theta_A, \Theta_B$,假设归一化参数为 $\lambda$,那么优化目标就可以表示为(论文里面少了一个$\frac{1}{2}$):
为了方便描述,我们简化一下,令 $u_{i}^{A}=\Theta_{A} x_{i}^{A}, u_{i}^{B}=\Theta_{B} x_{i}^{B}$,那么加密之后对应的 Loss 函数就可以写成以下形式。当然,也是为了方便,加密过程用双括号 $[![\cdot]!]$ 表示(在 Latex 中,用[\![ ]\!]表示,其中 \!表示一个单位的负距离 ),正常的括号还是用圆括号表示。
在梯度下降的过程中,对于第 $j$ 个参数有:
根据 SGD 的过程,现在问题就变成了参与方 A 和 B 如何得到 $\frac{\partial \mathcal{L}}{\partial \theta_{A,j}}$ 和 $\frac{\partial \mathcal{L}}{\partial \theta_{B,j}}$ 了。当然,在训练过程中,如果想知道 Loss 是多少,我们也可以算一下 Loss。接下来就面临着这么几个问题了:
- 偏导怎么算:在训练阶段,数据方 A 和数据方 B 怎么算出 $\frac{\partial \mathcal{L}}{\partial \theta_{A,j}}$ 和 $\frac{\partial \mathcal{L}}{\partial \theta_{B,j}}$;
- Loss 怎么算:在训练过程中,怎么对 Loss 进行跟踪;
- 模型如何使用:训练完成之后,怎么对数据进行预测。
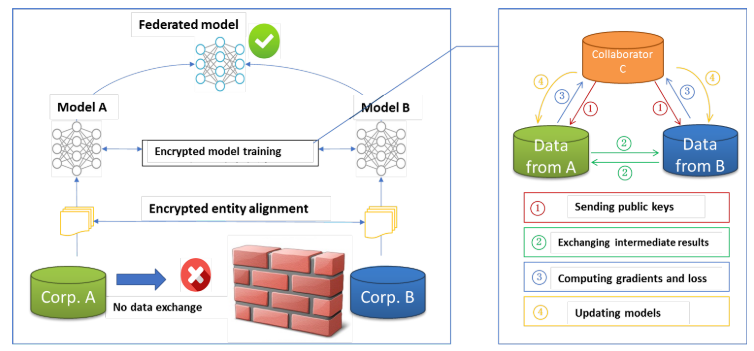
当然,以上的三个问题都需要在不知道数据情况下给算出来。为了实现这个需求呢,我们引入一个参与方 C(半诚信的)来计算这些东西,总体思路呢是 A 和 B 把自己能算的加密之后给 C,然后 C 把中间结果利用同态的性质和合并一下,再返还给 A 和 B,这时候 A 和 B 一解密,哎,知道要的结果了,就很美滋滋。然后根据这个流程,我们回头看看上面的三个问题怎么解决。
偏导怎么算
因为数据不能泄露,所以肯定要加密,可以看一下这个过程:
对于 A 来说,最右边的 $\lambda \theta_{A,j}$ 是可以自己算出来然后再加密的。对于第 $i$ 条数据,自己是有 $u_i^A$ 和 $x_j$ 的,因此我们看上式花括号的咋算
所以呢,实际上对于 A 来说,偏导就是:
所以呢,现在对于 A 来说怎么算偏导,思路就清晰了,大概是这么个流程:
- C 作为一个第三方,生成密钥并且把公钥发送给 A 和 B
- A 计算 $[![u_i^A]!]$,发给 C,B计算 $[![u_i^B - y_i ]!]$,发给C;
- C 计算 $[![u_i^A ]!] \oplus [![u_i^B - y_i ]!]$,发给 A;
- A 就可以本地计算 $\left([![u_i^A ]!] \oplus [![u_i^B - y_i ]!]\right)^{x_j}$,算出来之后再把 $[![\lambda\theta_{A,j}]!]$发送给 C;
- C 一通计算,得到了 $[![\frac{\partial \mathcal{L}}{\partial \theta_{A,j}}]!]$,并且把这个玩意解密之后发给 A;
- 最终 A 就得到了偏导了。
上述流程看着挺 OK 的,并且 B 也可以进行这些操作得到偏导,但是存在这么一个问题:C 可以解密得到有数据含义的中间数据。这当然是不被接受的。注意到同态的性质,任何一个人都能对密文进行处理。所以我们可以对以上流程这么改进一下:
- A 计算 $[![u_i^A]!]$,发给 B,B计算 $[![u_i^B - y_i ]!]$,然后 B 计算 $\left([![u_i^A ]!] \oplus [![u_i^B - y_i ]!]\right)$,然后发送给 A;
- A 然后就可以计算 $\left([![u_i^A ]!] \oplus [![u_i^B - y_i ]!]\right)^{x_j} \oplus … \oplus\left([![u_i^A ]!] \oplus [![u_i^B - y_i ]!]\right)^{x_j} \oplus [![\lambda \theta_{A,j}]!]$ 了,也就是说到这里偏导 $[![\frac{\partial \mathcal{L}}{\partial \theta_{A,j}}]!]$ 就算出来了,然后 A 本地生成随机数 $R_A$,计算 $[![\frac{\partial \mathcal{L}}{\partial \theta_{A,j}}]!] \oplus [![R_A]!]$,发送给 C;
- C 解密得到 $\frac{\partial \mathcal{L}}{\partial \theta_{A,j}} + R_A$,返还给 A;
- A 消去 $R_A$ 的影响,得到偏导,用于更新 $\theta_A$。
这个过程中,C 只作为中间数据的计算方,是得不到任何原始数据的。对于 A 来说,添加随机数也是为了防止 $C$ 得到偏导。
Loss 怎么算
实际上,知道梯度就可以完成模型参数更新的流程了。但是为了对 Loss 进行跟踪,一般参与方也需要知道每一轮的 Loss 值是多少,要是发现 Loss 不下降了,就知道模型训练的差不多了。回到开头,这个 Loss 为:
然后我们看左边的这一项,为了看着舒服, 上面的 $\frac{1}{2}$ 就先不讨论了,因此有:
我们假设 A 要算这个东西,那么可以这么做:
- A 计算 $[![(u_i^A)^2]!]$,B 计算 $[![(u_i^B-y_i)^2]!]$ 和 $[![2(u_i^B-y_i)]!]$,B 把计算结果发送给 A
- A 计算 $[![(u_i^A)^2]!] \oplus [![(u_i^B-y_i)^2]!] \oplus \left([![2(u_i^B-y_i)]!]^{u_i^A}\right)$ 得到 $\left[!!\left[(u_i^A+u_i^B-y_i)^2 \right]!!\right]$
根据这个原理,A 就能把 $[![L]!]$ 计算出来了,然后让 C 把这个解密就好了,当然,为了不让 C 获得中间数据,也可以加上一个随机数 $R_A$。当然这个 Loss 不仅仅是 A,B也是可以算的。
有了偏导和 loss 的计算方法,都被 A 和 B 知道了,也就是模型就可以训练成功了。
模型如何应用
由于 A 和 B 是分布式地获得了模型,数据也是分布在 A 和 B 两边,那么这个模型如何应用呢。也就是说,现在有一个新数据 $x=(x^A,x^B)$,怎么预测对应的 $y$ ?预测的过程中有(和训练过程一样,常数项已经隐含在 $x^A$ 或者 $x^B$ 中了):
所以各自计算然后汇总一下就可以估计出 $y$ 了,更进一步如果想保护 $y$ 的话(我们假设是 B 想算 $y$),可以让 B 根据 $[![y]!] = [![\theta_A x^A]!] \oplus [![\theta_B x^B]!] \oplus [![R_B]!]$,然后让 C 解密之后减去 $R_B$ 来得到 $y$。
关于模型的疑问
到这里为止,看上去一开始论文中出现的疑问就都消除了,但是,现在依然有存在着一些问题:
- 在模型训练的过程中,如果 $u_i^B-y_i$ 是负数怎么办?
- 在模型预测的过程中,如果 $y$ 是负数怎么办?
这个我目前也没想到好的方法,可能一种潜在的解决方案是把某些特征都加上一个量使得中间结果不出现负数吧。但是感觉这个解决方案不完美,因为 $u_i^B-y_i=\theta_B x^B - y_i$,这个 $\theta_B$ 是在训练过程中出现的,不可控的。对于第二个疑问,$y$ 出现负数,这个感觉可以解决,直接对所有的 $y_i$ 加上一个偏移量估计就好了。
参考资料
- Federated Machine Learning: Concept and Applications
- 吴恩达机器学习课程(4)-Linear Regression with Multiple Variables
本篇内容到这里就结束了,若想知道更多和信息安全有关的技术可在公众号留言。识别以下二维码可以成为本公众号的小粉丝,关注更多前沿技术。


