论文标题:How to Backdoor Federated Learning
作者:Eugene Bagdasaryan, Andreas Veit, Yiqing Hua, Deborah Estrin, Vitaly Shmatikov
论文链接:How to Backdoor Federated Learning
摘要
本文表明联邦学习易受某种 model-poisoning 攻击,这个攻击比只在训练集上的 poisoning 攻击更厉害。单个或多个恶意的参与者可以使用本文提出的 model replacement 在联合模型上注入后门,比如使得图片分类器对具备某一类特征的图片进行错误分类。本文在不同假设下对标准联邦学习任务进行了评估。
FL采用了安全聚合,因此模型不能在匿名前提下知道不同参与方对模型的贡献程度。同时本文也设计了约束技术,可以在训练过程中将攻击者的损失函数纳入防御规避中。
介绍
首先介绍了一下FL的基本概念,然后引出本文的出发点:FL 本质上是易受 model poisoning 攻击的,这是一种本文提出的新的攻击方法。FL给了所有的参与者对最终模型的直接影响能力,因此这个攻击比只针对数据集的毒化攻击更厉害。
我们表明,任一参与者可以直接替代掉最终的模型,并且使得:1)新的模型在FL任务上也具备相同的准确率;2)在后门任务上,新的模型被攻击者控制。比如前面提到的图像分类任务。图1展示了一个攻击的基本框架。
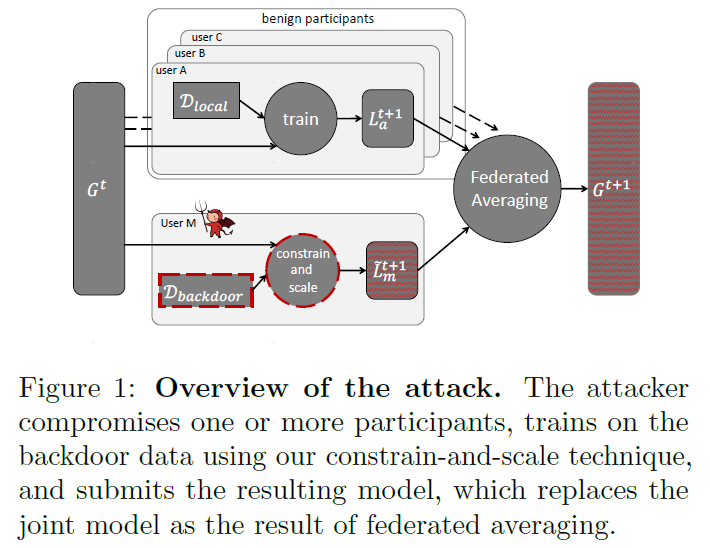
本文从两个具体的FL任务上展示了 model replacement 攻击的厉害:CIFAR-10 上的图片分类任务以及 Reddit corpus 上的 word prediction 任务。即使单一的攻击者只在训练过程中参与一轮,联合模型也能在后门攻击中获得100%的准确率(这句话翻译的可能不太对,大概意思就是这个攻击很666就是了)。攻击者仅需要控制不到1%的参与者,就可以在模型中注入后门,同时使得FL在主任务上不出现精度损失。
我们认为,FL 是易受后门攻击和其他 model poisoning 攻击的。首先,从数以万计参与者训练模型的时候,没办法保证其中没有恶意用户其次,FL 不能采取防御措施或者异常检测措施,因为需要用到参与者的模型更新数据,server端无法在保护隐私的前提下识别出恶意的数据。更深一步来说,FL采用安全聚合(secure aggregation),这更加防止 server 对参与者数据进行审计。
即使异常检测融入到了安全聚合过程中,model replacement攻击也是有效的。本文开发了一种通用的约束缩放技术,可以可以在攻击者的损失函数中规避异常检测,由此产生的模型甚至逃避了复杂的检测器。
相关工作
介绍了几个概念:
- Training-time attack
- Test-time attack
- Secure ML
- Participant-level differential privacy
- Byzantine-tolerant distributed learning
具体每个部分的相关工作可以阅读原文进行进一步了解。
联邦学习
联邦学习可以从数以万计设备上学习一个聚合的模型,这个用户数量 $n$ 是非常非常大的。在第 $t$ 轮,服务端选取 $m$ 个用户组成一个集合 $S_m$,然后把当前的联合模型 $G^t$ 发给他们。在这个过程中 $m$ 的选择需要权衡效率和学习速度。然后被选中的用户基于 $G^t$ 模型和本地数据训练得到本地模型 $L^{t+1}$,并且把差值 $L^{t+1}-G^t$ 返回给 server。然后更新完新的模型就是:
全局学习率控制着模型更新的比例,当$\eta=n/m$ 时候,新的模型就是这 $m$ 个用户的平均值了。
模型替代攻击
FL 是个新的趋势,训练过程可在数以万计终端设备部署。这也使得攻击者出现了新的攻击场景,无法保证那么多的用户不会出现恶意的攻击者。同时,现有的框架没有验证终端设备是否正确地执行了需要的操作,这也使得在联合模型中注入后门成为了可能。这一节讲模型替代攻击(Model Replacement Attack)。
威胁模型
FL 给了攻击者操控某一或部分用户的机会,比如在手机当中植入恶意软件。这也就意味着以下几点:1)攻击者控制本地数据;2)攻击者控制本地的训练过程和本地的参数,如学习率等;3)攻击者可以在上传数据用于server聚合前对本地模型结果进行修改,以及4)攻击者可以自适应地改变本地训练过程。
本文提到的过程和传统的 poisoning 攻击过程的不同之处在于,后者假定攻击者控制了一定比例训练数据,而本文假定攻击者完全控制了一个或某些参与者。
Objectives of the attack. 攻击者想要得到一个模型,使得对于正常数据可以正常识别,同时对于想要攻击的数据可以留下后门。作者提出了一种“语义后门”(semantic backdoors)的新类型后门,比如在分类问题中,把带有条纹图案的汽车分类成鸟。
构建攻击模型
Naive approach. 攻击者可以基于 backdoored 的数据训练本地模型,根据论文[Gu 2017],每个 batch 应当同时包含正常数据和 backdoored 的数据,这样子模型可以知道这二者的区别。同时,攻击者可以修改本地的学习率和 epochs,这样使得模型可以很好地过拟合。
不过这种朴素方法不适合 FL,汇聚者可以消去 backdoored 模型的贡献,这样汇聚的模型就会遗忘掉后门数据。这样子,攻击者需要被频繁选择才能达到攻击效果,同时,毒化的过程会很慢。本文把这样的方法作为 baseline。
Model replacement: 在这种方法下,攻击者试图直接把全局更新的模型 $G^{t+1}$ 替代为想要的模型 $X$,如下面的公式所示:
由于训练数据是 non-i.i.d. 的,每个本地模型实际上都离 $G^t$ 很遥远,不妨假设这个攻击者就是第$m$个用户,那么就是有:
当全局模型开始收敛时,差不多会有:$\sum_{i=1}^{m-1}(L_i^{t+1}-G^t) \approx 0$,也就是说 $L_m^{t+1}$ 和最终模型之间大概有这么个关系:
攻击者需要按比例 $\gamma=\frac{\eta}{n}$ 放大自己的权重使得在 model averaging 阶段,后门可以保留,并且模型被 $X$ 所替代,这在 FL 的每一轮中都有效,尤其在模型快要收敛的时候更加有效。
Estimating global parameters. 假如攻击者不知道 $n,\eta$ ,他可以估计一个比例 $\gamma$ ,通过逐次慢慢增大 $\gamma$ 的方式来达到后门攻击。虽然这样子不能完全替代最终的模型为 $X$,但是可以在后门数据上达到高准确性。
模型替代方法可以使得要植入的模型可以在 model averaging 的过程中活下来,并且这是一种 single-shot attack,最终的模型在正常数据上可以使用,同时留有后门。
提高持久性,逃避异常检测
在迭代过程中,server 每次都是选取几个 clients 然后用他们的数据进行训练,不会恰好每次都会选到我们要部署的攻击者。那么怎么让攻击者想要注入的模型在后面的迭代过程中可以进行的保留呢。
实际上,本论文的攻击模型包含两个任务的学习过程,学习正常任务和学习后门任务,攻击者希望这两个任务上模型都能获得较高的准确率。本文采用了一些技术来使得注入的模型可以更加持久,比如在攻击者训练过程中降低学习率(我也没搞懂为啥可以)。
FL 一般使用安全聚合来防止 server 知道参与者的数据,因此在 FL 中,没有方法可以知道那个客户是恶意的,也无法知道注入的模型是哪个客户发过来的。如果没有安全聚合的话,隐私就无法保证了,这时候 server 可能可以通过检测异常的方式找到异常的 client。由于我们在攻击的过程中,注入的模型使用了 $\frac{n}{\eta}$ 进行了放大,所以 server 很容易就知道哪个是攻击者并将其过滤。
Constrain-and-scale. 现在开始介绍一种可以对正常数据和后门数据训练的方法,同时可以逃过 server 的检测。本文采用了这样的目标是可以使得:1)可以训练高精度模型;2)penalizes it for deviating from what the aggregator considers “normal”。当然,也假设异常检测方法是被攻击者所知道的。

算法1显示了 constrain-and-scale 方法,这个loss添加了一个额外项 $\mathcal{L}_{a n o}$:
因为攻击者的数据包含正常数据和后门数据,$\mathcal{L}_{\operatorname{class}}$ 标识正常数据和后门数据上的准确性,然后 $\mathcal{L}_{\operatorname{ano}}$ 标识任意类型异常检测,比如权重上的 $p$-norm。超参数 $\alpha$ 控制比例。
实验分析
本文研究了 FL 在图片分类和单词预测上的应用。
图像分类
Image classification 采用了CIFAR-10 数据集,用了100个参与者,每轮迭代随机选10个用户,用了轻量级的 ResNet18 CNN 模型,有27万个参数,然后介绍了一下怎么模拟 non-iid 情况。每个参与者本地用了两个epochs,并且学习率是0.1。
Backdoors. 假定攻击者想要联合模型对汽车进行分类,同时对含有某一类特征的汽车的需要注入后门使得模型分类错误,对于其他汽车分类正确。相对于pixel-pattern的后门攻击,这个方法不需要攻击者在推测期间对数据进行修正。
作者选了三个特征用于攻击:绿色的车(30个图),有赛车条纹的车(21个图)和背景有竖直条纹的车(12个图),如下图所示。然后坐着对数据进行分割使得仅仅攻击者含有后门特征的数据,当然这不是本质需求。如果后门特征和正常用户的其他特征相似,攻击者依然可以成功攻击,不过联合模型会很快地在迭代过程中忘记后门。然后还介绍了一些其他的细节,需要详细了解的时候可以再回头看原文。

词预测
词预测(word prediction)也是FL下比较著名的任务,因为训练数据为文本,比较敏感,同时也杜绝中心化的收集(比如打字记录)。然后再NLP中,词预测也是一个典型任务。
作者使用了别人的案例代码(参考论文描述),然后用了2层LSTM模型,有 $10^7$ 个参数,用了 Reddit 数据集,假定每个用户是独立的参与者的情况下,为了保证每个用户足够的数据量,坐着过绿了少于150和多于500个发表内容的用户,这样子就剩下 83,293 个用户,平均每个用户有247次发表内容。在训练数据集中,每一次发表内容被认为是一句话。然后根据别人的实验,本实验中,每一轮迭代随机选了100个用户,每个用户在本地用了2epoch,学习率是20。然后测试数据集为前一个月的5034个发表记录。
Backdoors. 攻击者想要当某个句子以特定单词开头时,预测给定的单词。如下图所示:

这种语义攻击不需要在推理阶段对输入进行修正。即使一个推荐的单词就很可能改变某些用户对某些事情的看法。为了训练模型,训练数据被串成 $T_{seq}=64$ 的长度,每个batch包含20个这样的句子。loss的计算过程如图3(a)所示。

攻击者的目标是当输入是触发句的时候输出给定单词,如图 3(b) 所示。为了为后门提供不同的上下文,从而提供模型的健壮性,作者保持批处理中的每个序列不变,但将其后缀替换为以所选单词结尾的触发语句。实际上,攻击者教导当前的全局模型 $G^t$ 预测触发语句中的这个单词,而不做任何其他更改。结果模型类似于 $G^t$,它有助于在主要任务上保持良好的准确性,从而跳过异常检测。
实验结果
所有的实验用了100轮的FL,如果某一轮选择了多个攻击者,那么他们会把这些数据添加到一个后门模型中。然后 baseline 也在前面讲过了。
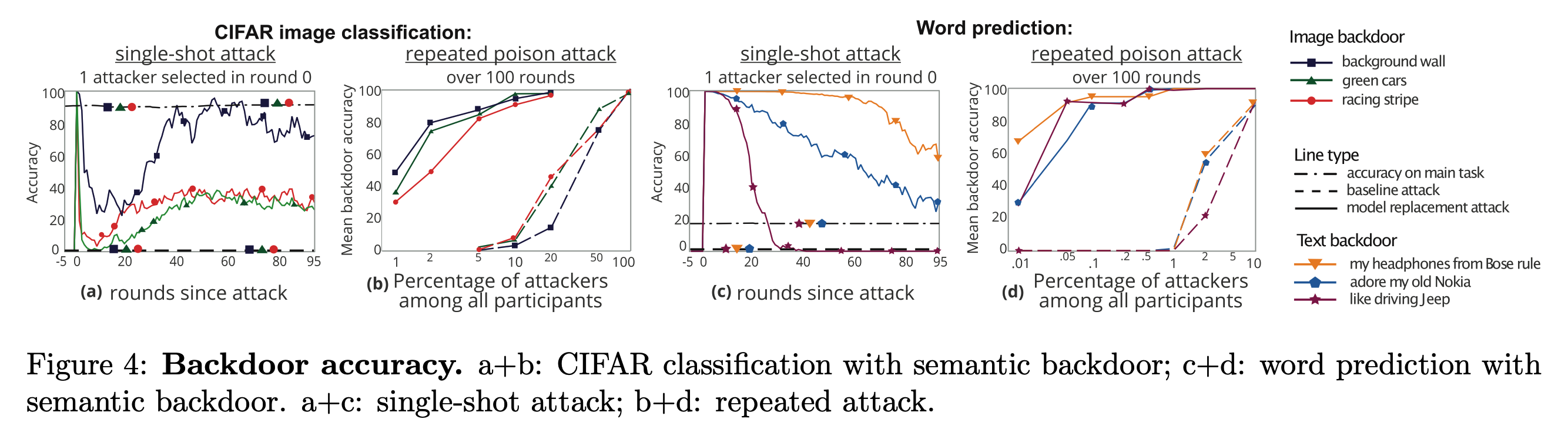
Single-shot attack. 图4(a) 和图 4(c) 表示了single-shot攻击的实验结果,这个攻击大概意思就是说单一轮次只有一个单一的攻击者,并且旨在前5轮迭代中有攻击行为。当攻击者把梯度发过去之后,后门任务的准确度将会是 100%,然后随着迭代的进行,后门任务的准确率会下降,主任务的准确率将不会受到影响。与之对比,传统方法下的攻击方法无法注入后门。
有些后门就会比其他后门更容易注入,比如“有条纹的墙”这个后门就比“绿色的车”效果更好。作者猜测这是因为绿色的车和正常的良好数据的分布会更接近,因此很容易在迭代的过程中被覆盖。同样对于单词预测也有类似的情况。
Repeated attack. 如果攻击者控制了多个用户那么就有更多的攻击方法了,图4(b) 和图4(d) 展示了随着受控制用户比例对注入的影响。给定比例下,本文所提出的方法会比baseline方法具备更高的后门注入准确率。
总结
总的来说就是本文提出了一种新的FL攻击模型,并且可以注入语义信息从而不容易被发现模型被注入了后门。但是呢我觉得有这么个问题,根据注入的流程,攻击者(恶意参与者)得知道其他正常参与者的梯度才能构造出当前轮的梯度。那么server是不是每次丢掉最后一个用户的梯度就可以避免这种攻击了。
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


