从官网https://www.tpc.org/information/who/whoweare5.asp找到下载页面,输入一些信息和邮箱之后就可以从邮箱获取下载链接了。下载完解压的东西如下图所示:

首先进入到dbgen文件夹,这是用来生成database的目录,打开makefile.suite文件,找到这个地方:
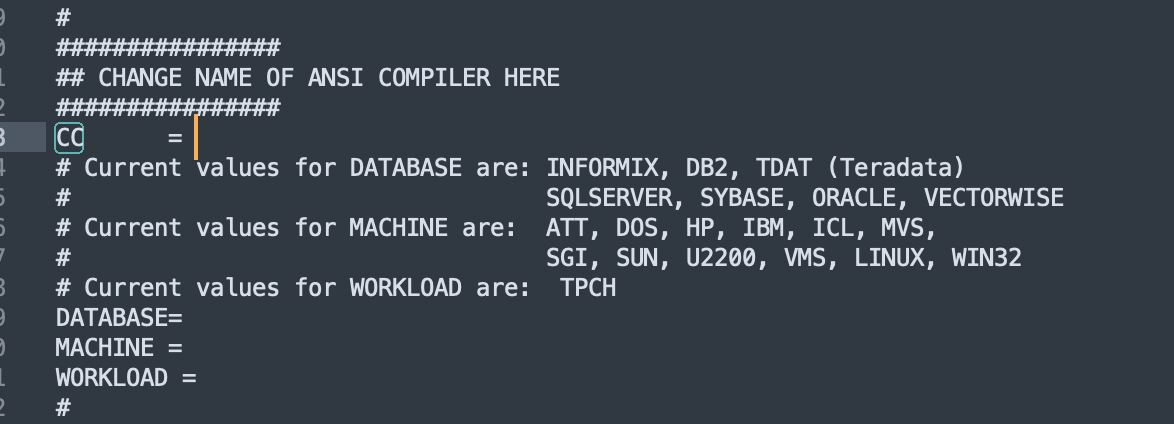
填写以下的信息:
1 | CC = GCC |
注意,虽然咱们是MacOS,但是里面的Machine选项还是填写LINUX。一般网上说直接make就好了,但是出现以下错误:

要解决这个问题,需要把makefile.suite重命名成makefile,就可以。接下来主要输入两个命令:
1 | make |
首先输入make进行编译,编译的过程会碰到这么个问题:
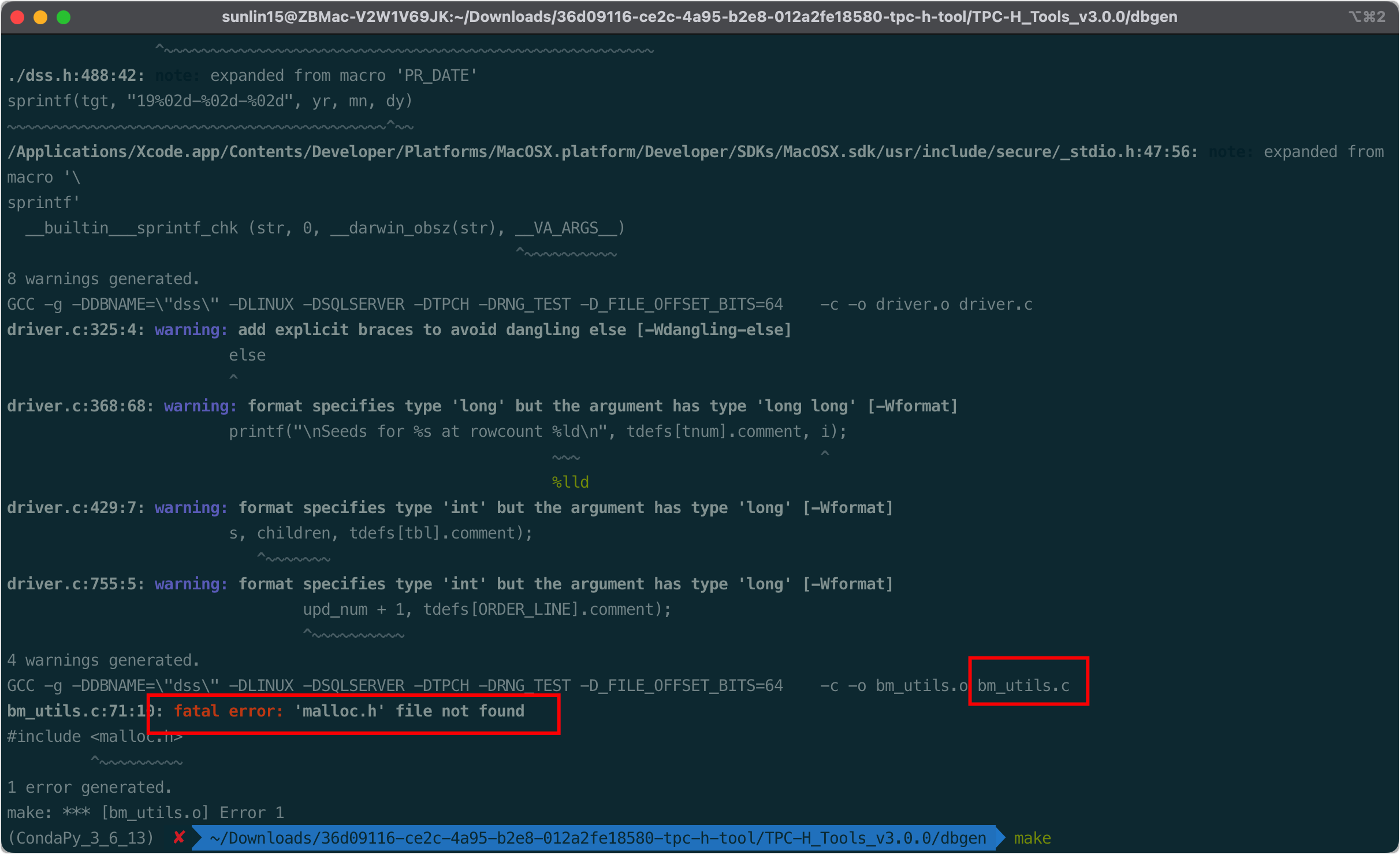
上面说bm_utils.c这个文件里面找不到malloc.h,网上查了一下,是mac平台下这个文件在sys目录下,这个对应的代码改成:
1 |
相同的错误按照这个方法改就行。然后就可以用第二个命令生成1G的文件。一共会生成8张数据表,如下图所示:
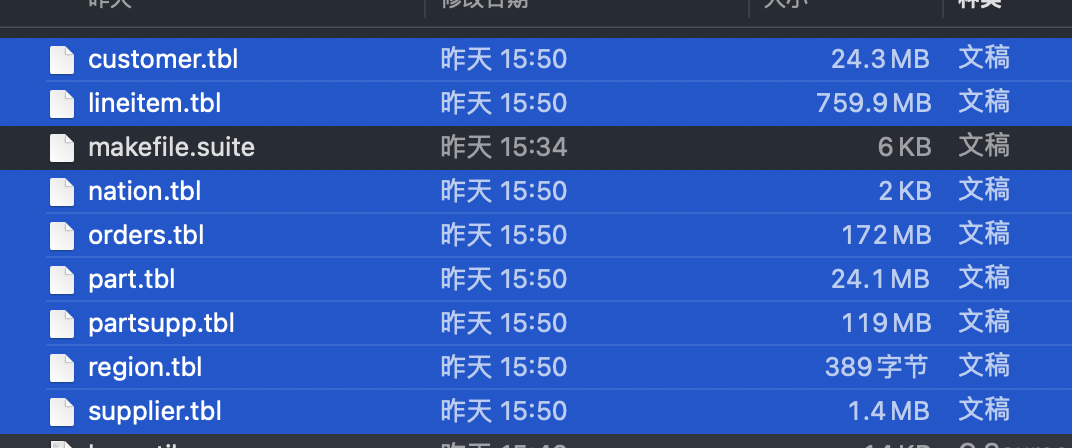
生成的数据就在dbgen文件目录下。到此,数据就生成完毕了。数据表的信息在其技术文档中有描述。为了使用pyspark读取方便,需要在每个数据文件的第一行加上表头,如下:
1 | # customer |
采用pyspark,可以用这个方式读取:
1 | from pyspark.sql import SparkSession |

