之前记录过用pyspark中对column采用udf,但是如果我们更进一步,udf中的内容是需要添加噪声的呢,该怎么办?这里贴一个解决方法,如下:
1 | # -*- coding: utf-8 -*- |
运行的结果为:
1 | +----+---+-----+ |
接下来神奇的现象就发生了,在两个log中,可以发现噪声的大小竟然是一模一样的。如下图所示:
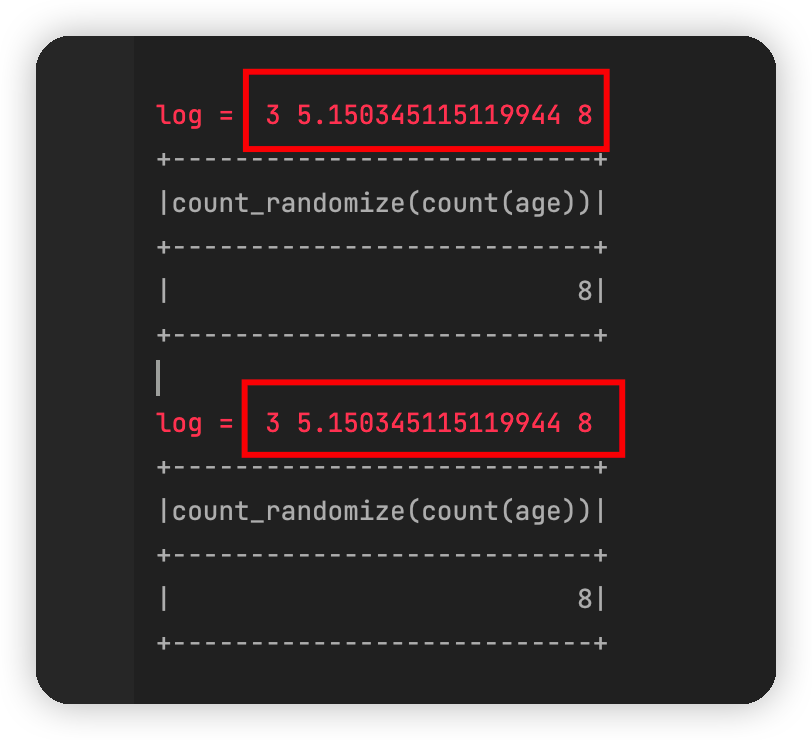
这不应该啊,在numpy中,即使是两次采用 np.random.laplace(0,1)产生的噪声也是不一样的。而且,还有神奇的是,代码中明明设定了 np.random.seed(0),重复运行该代码,每次产生的噪声竟然是不一样的,比如再运行一下,得到这样的结果:
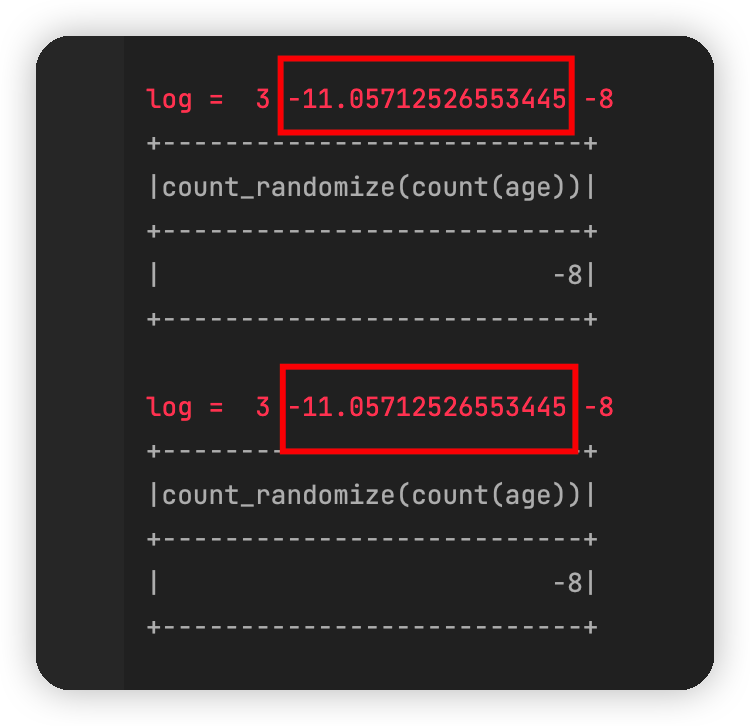
到目前为止,我也没有找到其本质的原因,但是大概率是pyspark的问题。这个猜测在一定程度上成立,当然由于我不了解pyspark的底层原理,这个猜测不一定靠得住。
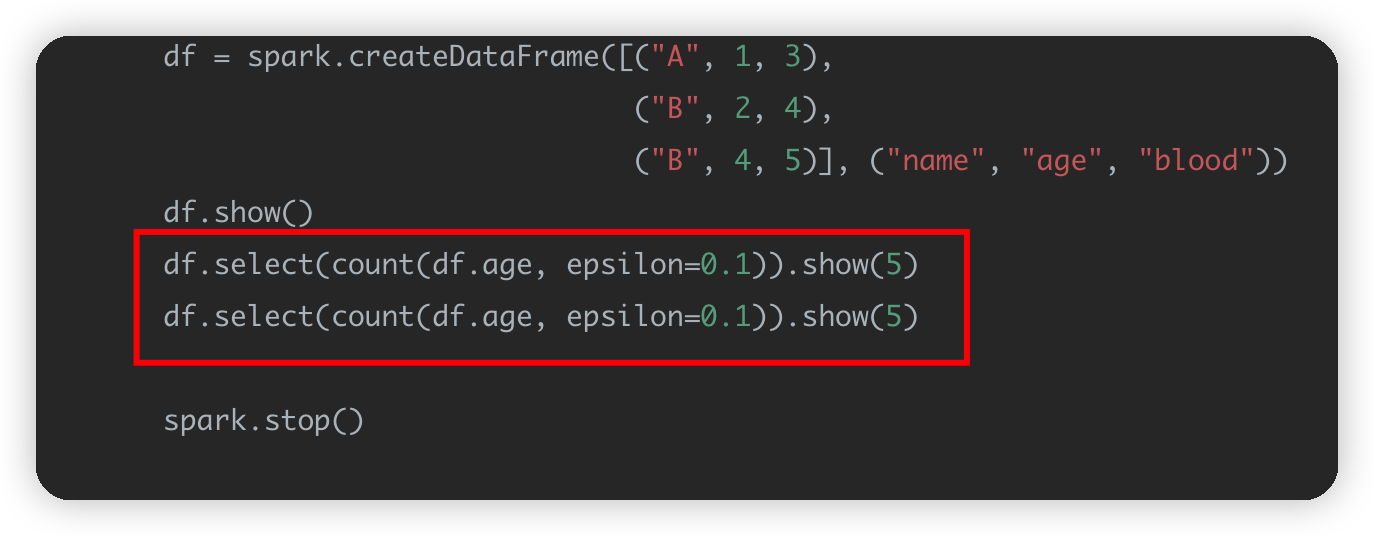
在运行代码的时候,spark会用多线程方式去运行代码,这时候,上面的代码就会被分配到2个线程去运行,而每个线程的初始化种子又是一样的,因此就产生了相同的随机数。这就部分解释了这个现象。更进一步我们可以把main中的local[2]改成local[2]然后把df.select重复4次,代码如下:
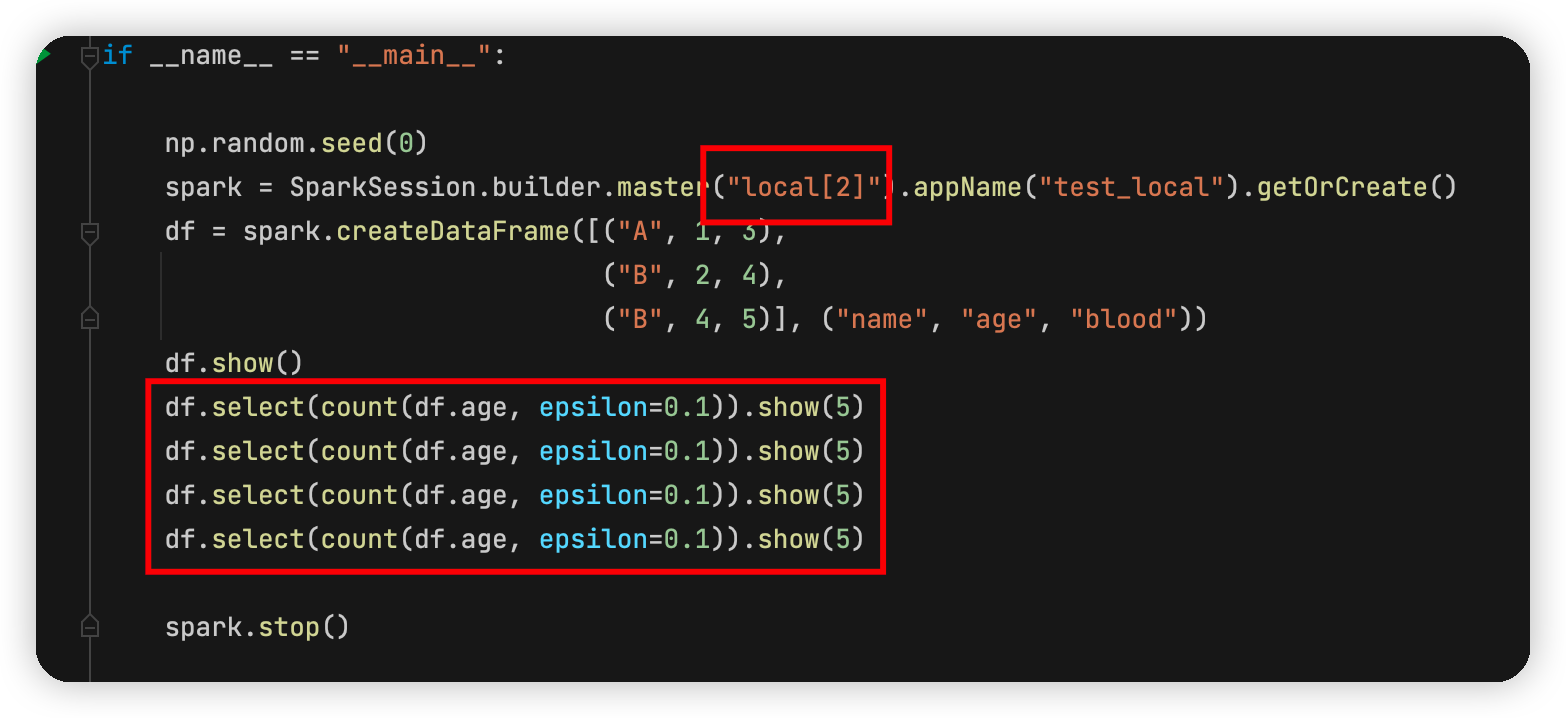
可以看到四次噪声是这么个情况:
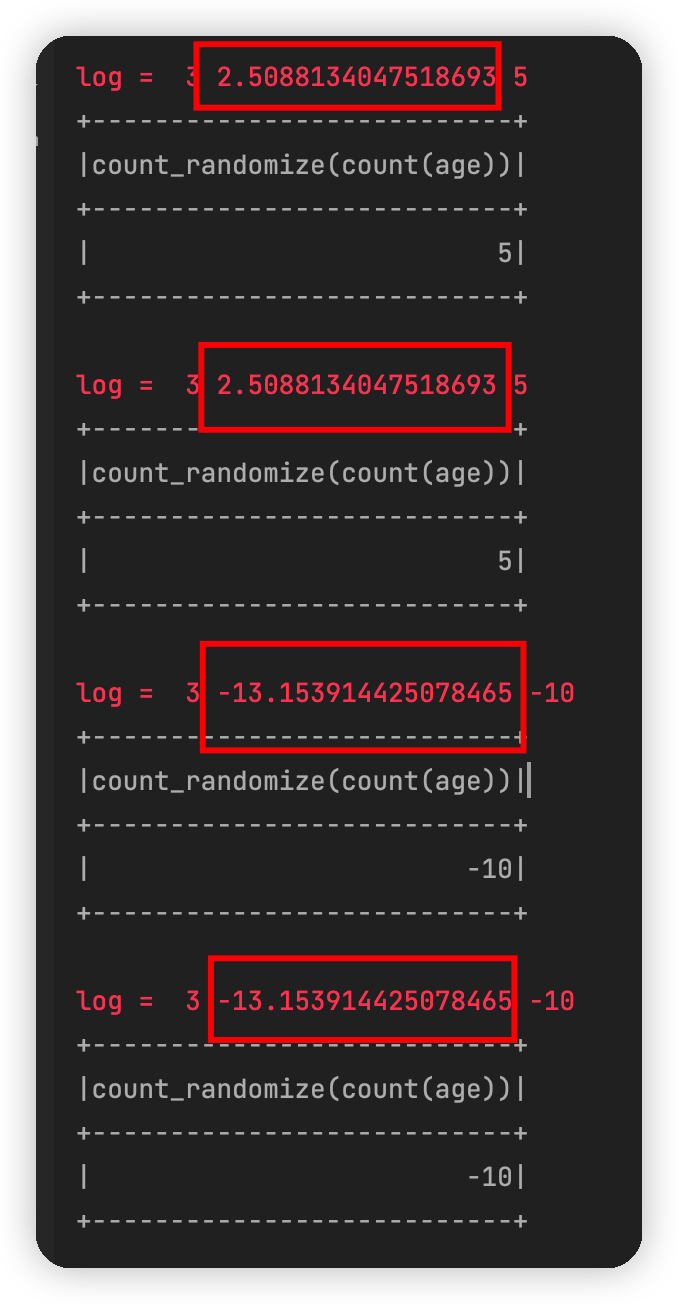
为什么我说这个解释靠不住呢,因为如果多次运行上面的代码,有时候也会出现不是这个规律的。本质问题还是因为我们不清楚spark的底层是如何分配线程去并计算的。
当然,这里一开始也怀疑过是不是 numpy的问题,
解决思路
方法1
有了上面的分析,自然而然地就可以有第一种解决思路,就是,我们只用一个线程去做这么个事情,这就能保证每次的噪声不一样了。
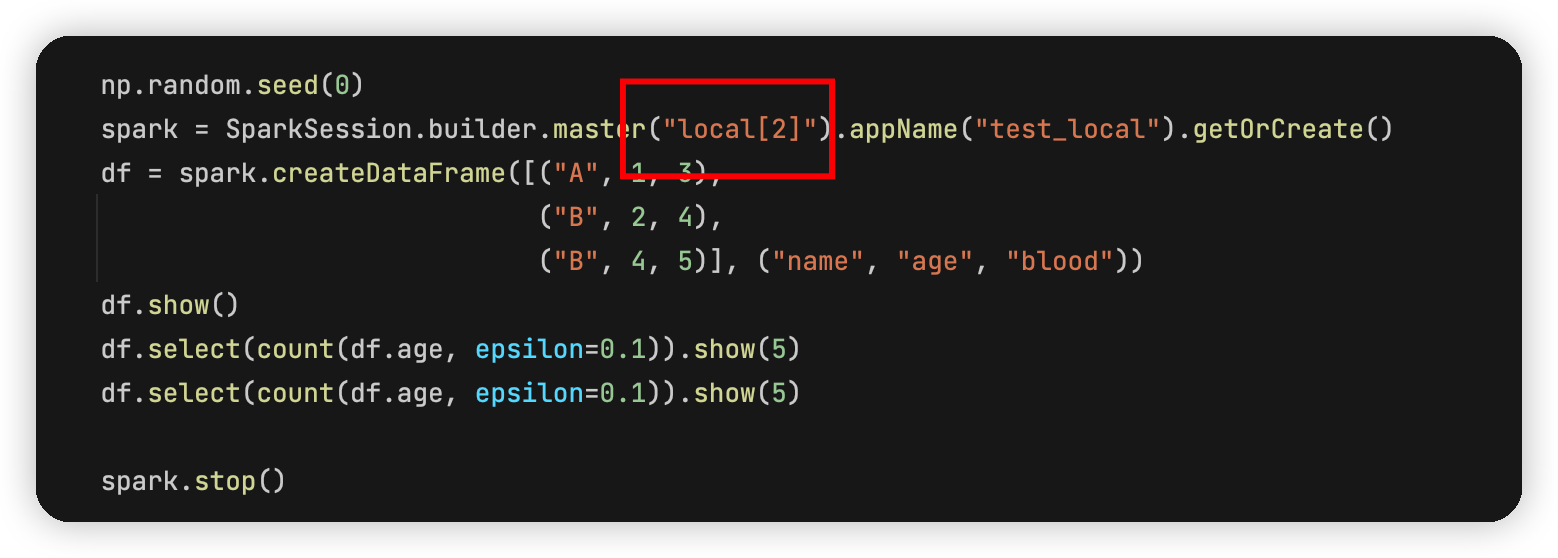
在这里把local[2]改成local[1],这样spark就会用一个线程去跑代码,两个语句就会产生不同的噪声,结果如图:
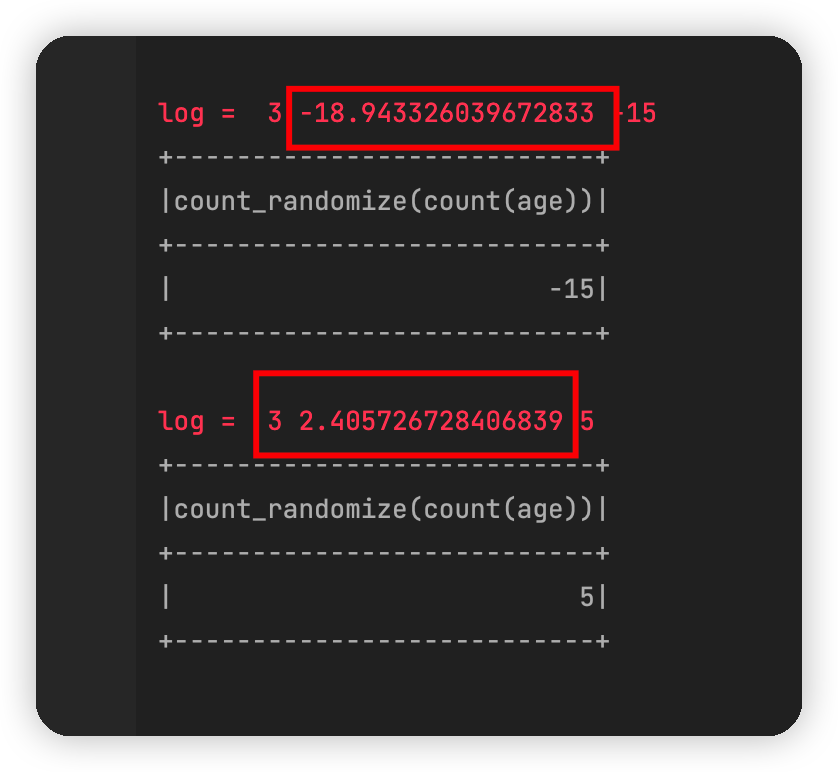
方法2
方法1通过只采用一个线程的方式去解决不同线程的随机数种子一样的问题。在代码的实际运行过程中,只采用一个线程有时候效率会比较低,不太适合
这里需要回顾这样一个问题:如何成生一个比较好的随机数?我目前想到的答案是利用时间当种子,然后去产生随机数。即使spark是并行地去计算,比如用两个线程,即使两个线程初始的随机种子是一样的,我在产生噪声前用系统时间更新随机种子,那两个线程应该生成不同的随机数。这个原理自然而然是可行的。
因此,可以这么修改:
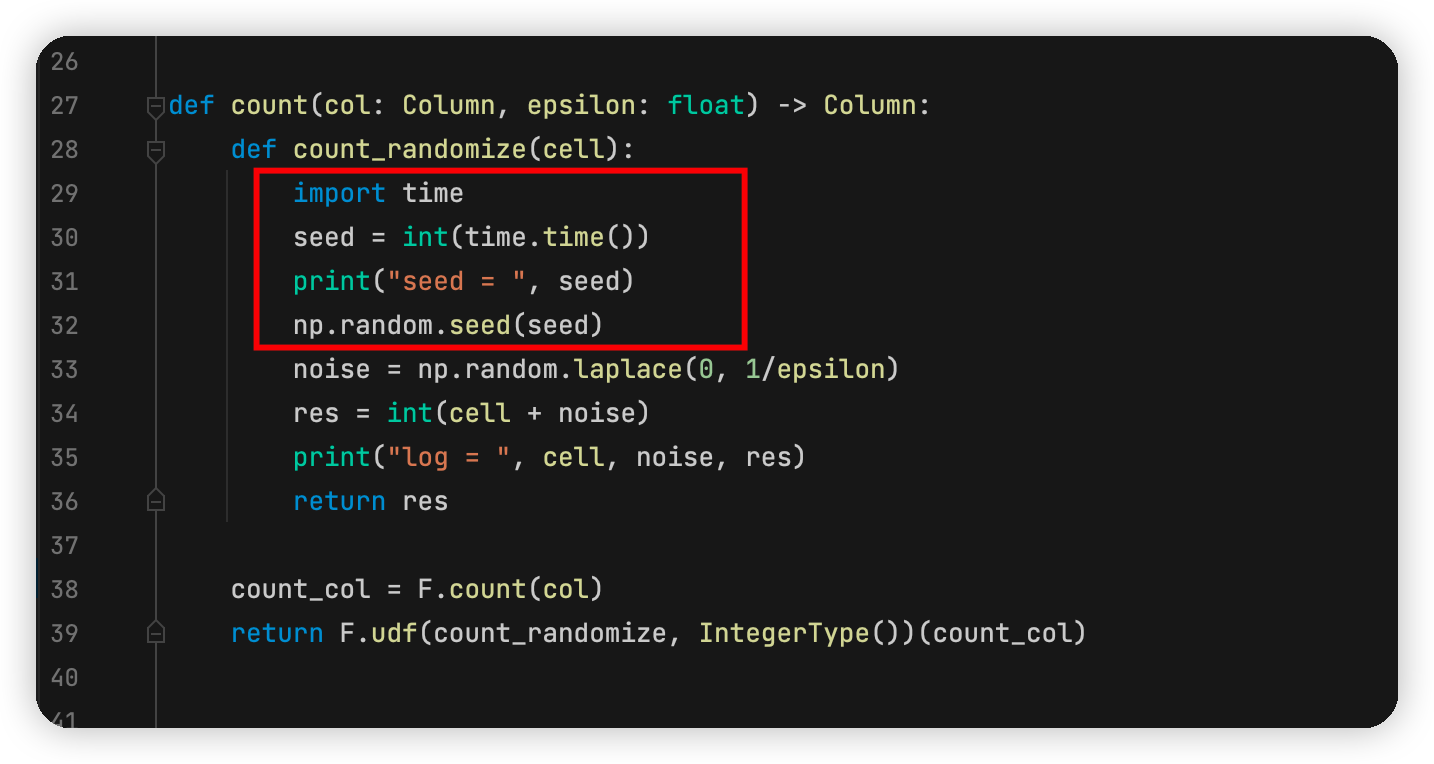
我们还是用两个线程去运行代码,理论上可行的方案,得到的结果为:
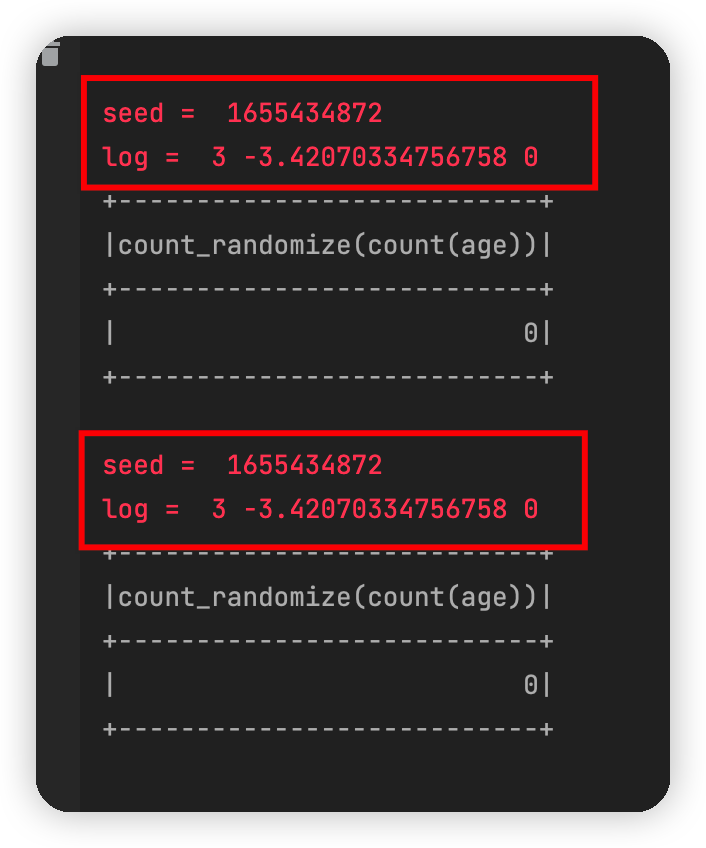
接下来出乎意料的结果又来了,两个线程的随机种子竟然是一样的。这不禁让我怀疑这个方法的可行性。仔细思考之后,觉得应该是时间精度不高,理论上两个代码不会完全“同时发生”的。于是又进行了这样的修改:
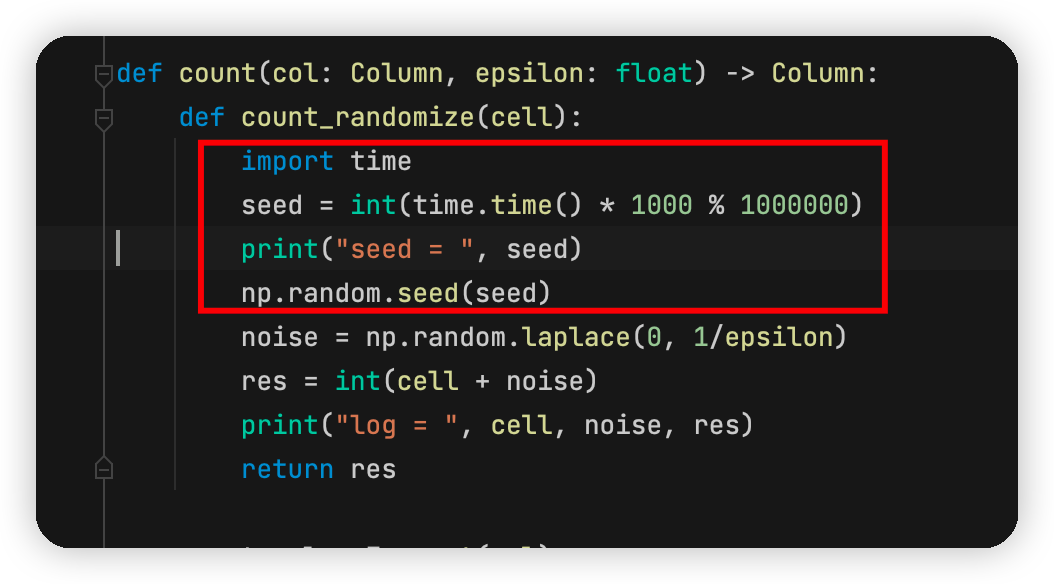
这样情况下,结果为:
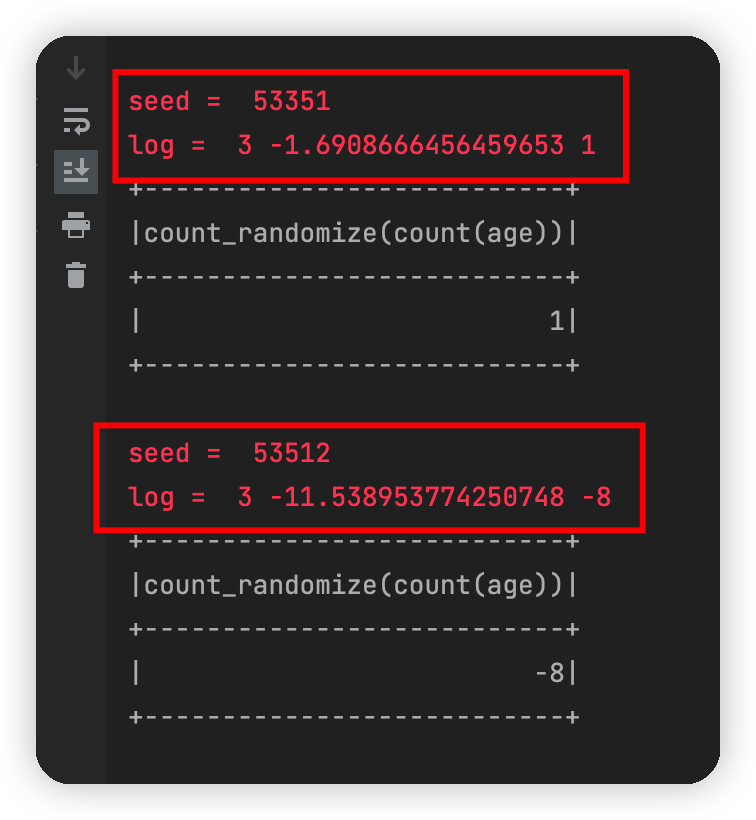
可见,只是在并行过程中,两个线程取到的时间“基本一致”,为了使得两个seed差别更大,我们最终的代码这样即可:
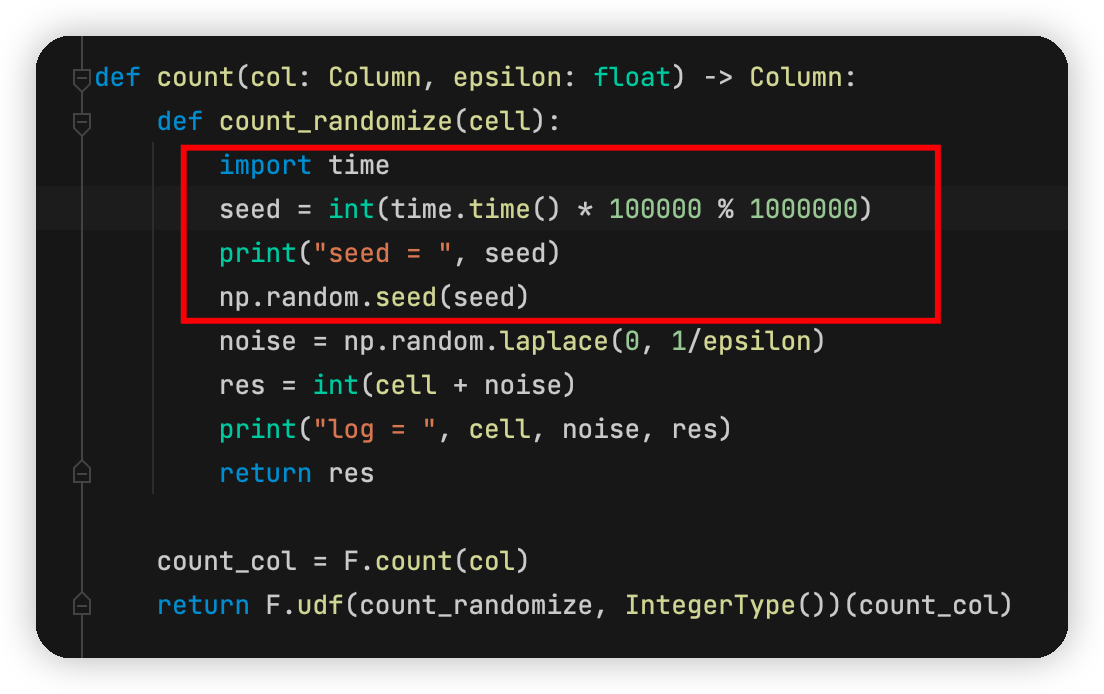
这种情况下的输出为:
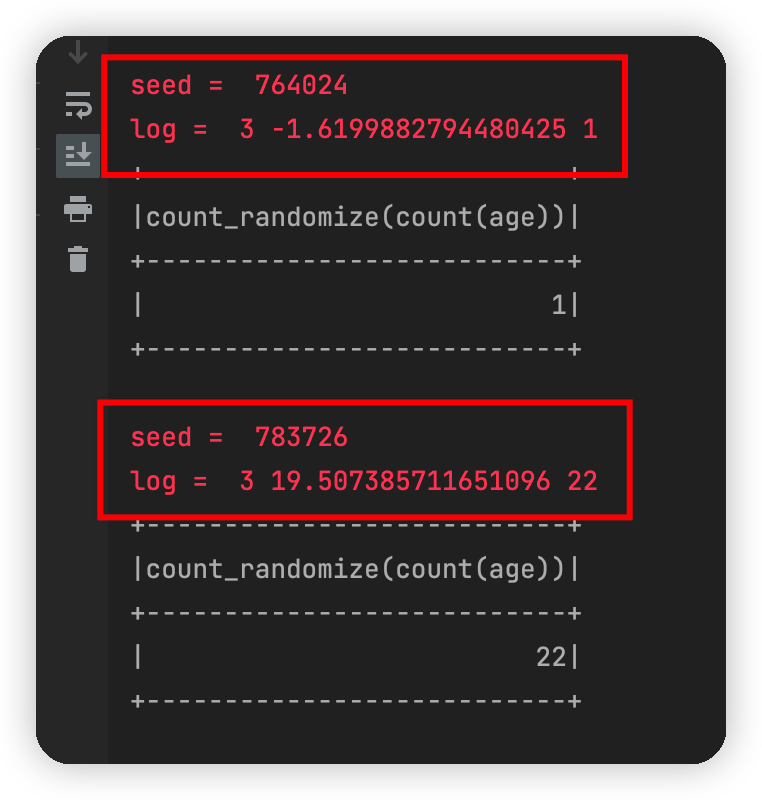
这就是第二种方法的解决思路了,最终全部代码如下;
1 | # -*- coding: utf-8 -*- |
这样可以比较好的解决目前遇到的问题,不过有强迫症的我总觉得在每次产生噪声的时候重置seed这个处理方式不太优雅,但是目前我也没有想到更好地解决方法。
方法3
这个方法是组里同学乐乐提出的,其思想为:在代码运行之初,自己创立一个线程用来产生随机数。然后当spark中的代码需要用到随机数的时候,去向那个线程请求随机数。可以类比为,自己创建了一个产生随机数的服务,其他任何地方的随机数都是我这个随机数服务提供的。
这个方法感觉理论上可行,但是我的代码基础有限,就没有去实现和测试了。感觉思路确实值得借鉴就在这里列出来了。
总结
当时也是不知道哪根筋不对,把df.select.count那个语句运行了两次突然发现的这个bug,如果当时只运行了一次,就会自然而然认为自己的代码是正确的了,可能就少发现了一个潜在的bug。还是要多多学习。网上搜了很多,也许是关键词不对,没有找到相关的东西。
这个bug从发现到暂时解决差不多用了一天的时间,组里四个小伙伴(畅哥,阿圳,乐乐)一起研究到十一点也没有完全搞透底层逻辑。好在算是暂时能处理这个bug了。
目前知识有限,只能提供较为粗浅的解决思路。如果看到这篇文章的小伙伴有更好的解决方法,也欢迎联系我。

