前言
Weekly DP 是本公众号每周更新的一个栏目,更新上一周 arXiv 上面和 DP 有关的论文。最开始的时候为了提供这个功能,每天早上的第一个工作任务就是浏览一下当天的 paper list,然后一个个点开看看摘要,如果和 DP 有关系的,就做个记录。最后每周整理一下以公众号的形式发出来。
后来发现,这个过程其实重复性劳动比较多,就想着能否自动化一下这个流程。就有了这篇文章。因为第一次接触这类东西,逻辑可能有待优化,感兴趣的同学可以看下我的思路并提出优化。也可以直接进到我的 github(weekly-papers-in-arXiv),获取对应的开源代码并运行。此方案不限于 DP 哦,也可以用于 arXiv 上的其他领域。
思路
目标
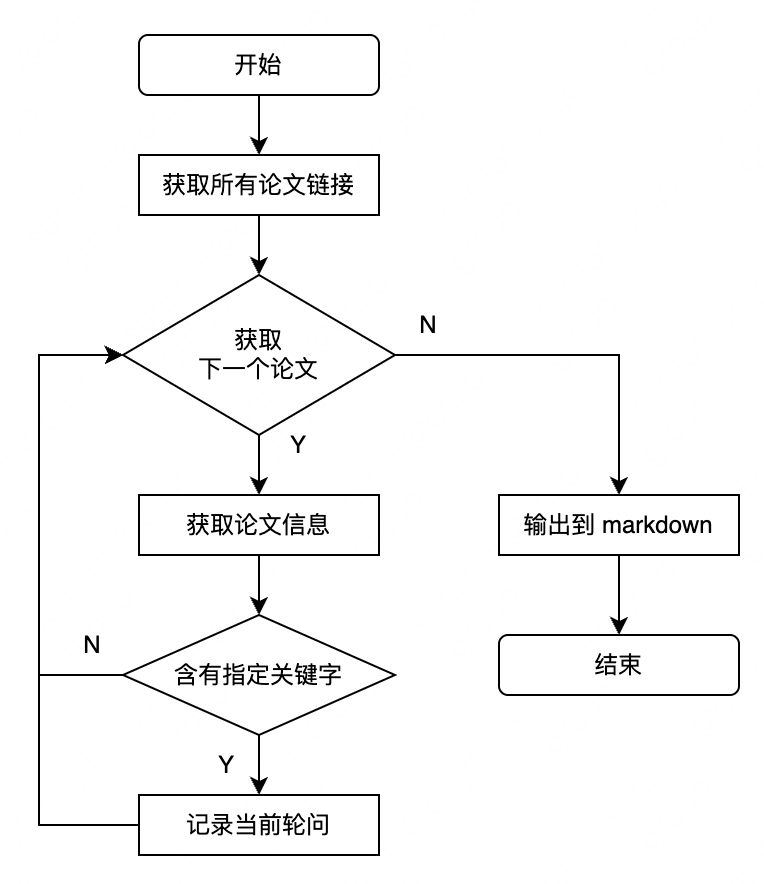
最终目标是希望运行一个脚本,根据关键字和浏览类目自动生成markdown文件。所以思路大概就是这个样子:
- 找到一个领域及其对应的连接,如:https://arxiv.org/list/cs.CR/recent
- 获取最近一周有哪些文章
- 遍历每个文章,筛选出含有指定关键词的文章
- 将结果转换为markdown形式
流程图大概就长这么个样子
首先,要自动化分析,肯定是离不开爬虫的。arXiv有着自己的“君子协议”,规定哪些内容可以爬,一般在域名对应的robots.txt可以看到,如下:
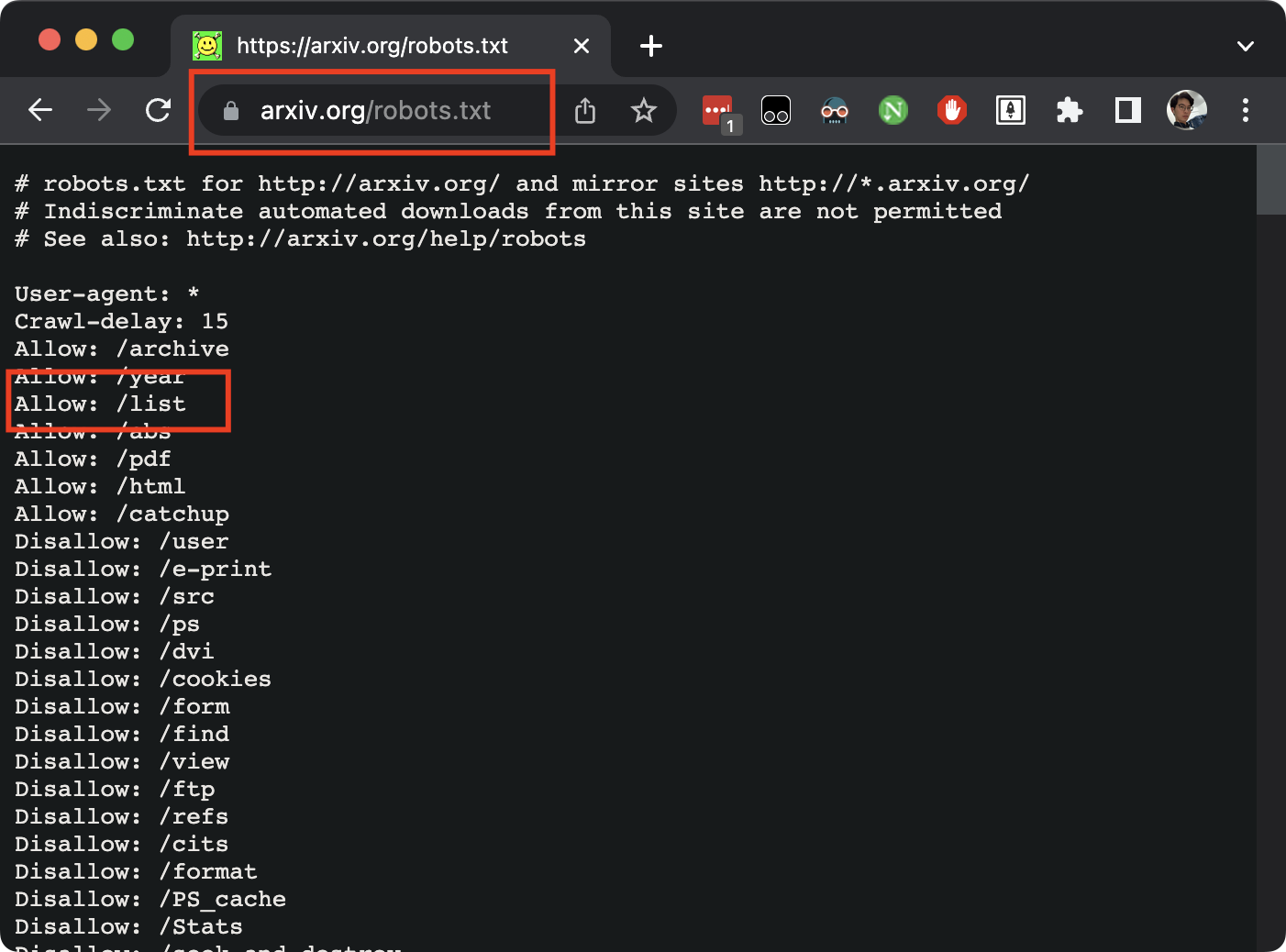
很巧,我们即将要爬的链接是合法的,所以就可以放心地去做了。
第一步:写个大框架
1 | def get_weekly_papers(keywords, link): |
第二步:get_page_content实现
这部分其实很简单,借助 request 库即可实现。代码为:
1 | def get_page_content(link: str): |
第三步:get_arxiv_ids_from_content实现
上一步获得的网页代码,其实本质上和浏览器查看网页源代码看到的东西是一样的。接下来就需要从网页源代码中获取到,过去一周有哪些论文的id。以日常浏览arXiv为例,这是用户界面:
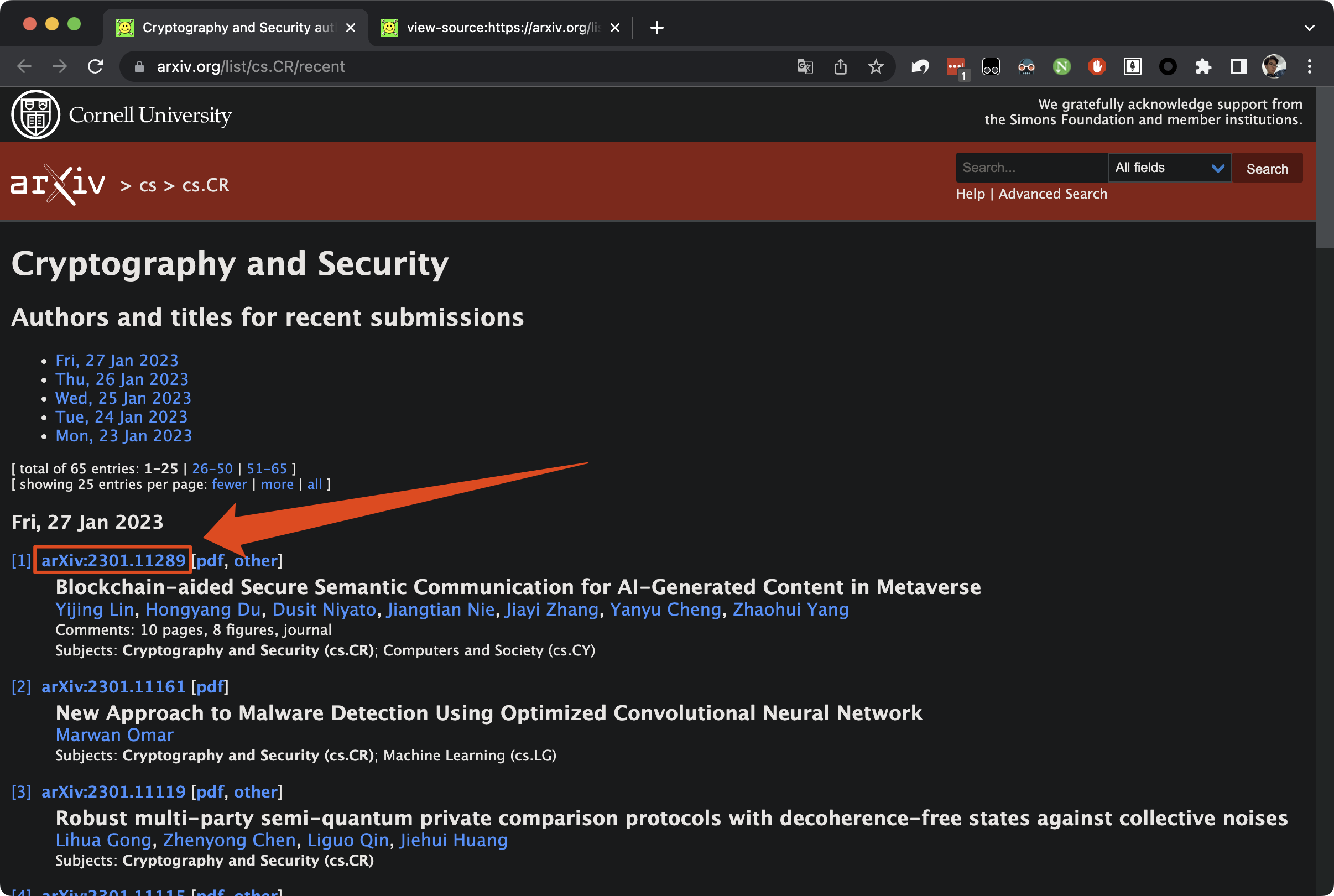
对于第一篇文章,我就希望可以获取到:2301.11289,这样自己进行一个网页的拼接就能访问到其摘要了。如下图:
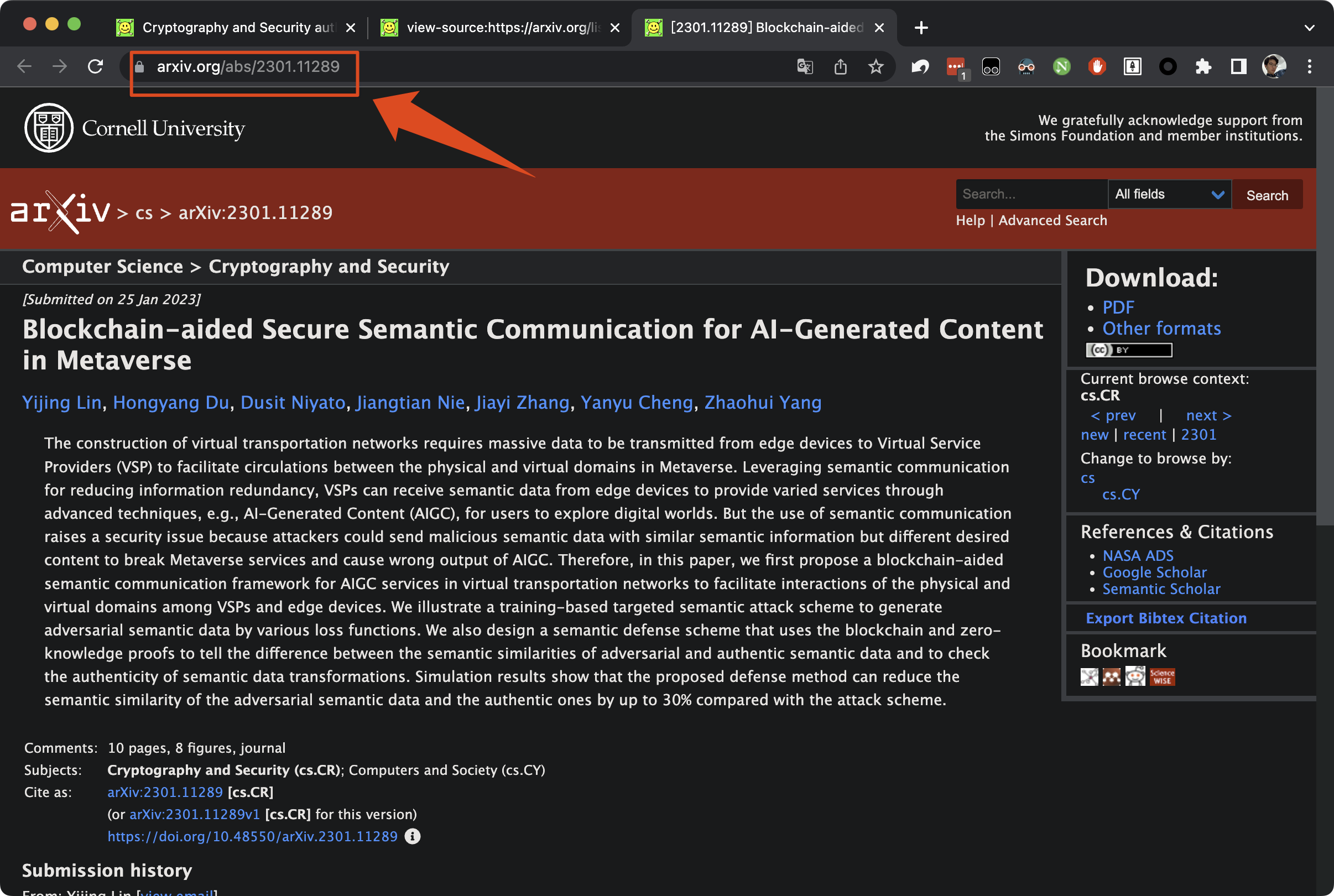
所以回到上一步获取到的 page content,观察一下其源代码结构,就可以发现可以用正则表达式去获取。

如上图,我从href="/abs/xxx.xxxx"中对 arxiv_id 进行了获取。当然也可以从其他地方获取到。正则表达式部分也不涉及复杂的规则。
这部分对应的代码为:
1 | def get_arxiv_ids_from_content(page_content): |
第四步:get_papers实现
这部分最初打算自己实现,去每篇论文的链接中把作者,摘要等抠出来的。后来发现 arXiv 提供了一个官方库,链接为:https://pypi.org/project/arxiv/。其最主要的用法是:
1 | papers = arxiv.Search(id_list=arxiv_ids) |
然后返回的 papers 就是一个迭代器,里面的每个元素中都有 paper.summary, paper.authors 等信息。
第五步:is_related实现
此部分就是一个双重循环,对于每个关键字看其是否出现摘要中即可。对应代码为:
1 | def is_related(abstract, keywords): |
第六步:write2md实现
经过上一步,含关键字的论文就被筛选出来了。接下来把内容输出到 markdown 文件。我做了一个额外的事情,就是把相关的论文按天进行排序,形成了一个 time_papers = {day: papers}的字典结构。这样写入markdown的时候,一级标题就是对应的日期了。此部分代码如下:
1 | def write_markdown(time_list, time_papers, filename): |
开源代码
本文的代码地址为:weekly-papers-in-arXiv。读者可根据自己需求自行更改,比如一键寻找 CV 领域含关键字 CNN 的文章。
后话
有的时候有了工具完成同样的事情,自己主观上就有点懈怠了。前言里面提到一开始是每天都会自己主动浏览一下论文摘要的,虽不一定完全了解前沿动态,但至少留了个印象。有了这个工具之后,自己反而不怎么看了。值得反思。

